






 BTC/HKD+0.27%
BTC/HKD+0.27% ETH/HKD+0.44%
ETH/HKD+0.44% LTC/HKD-1.08%
LTC/HKD-1.08% DOT/HKD+0.55%
DOT/HKD+0.55% ADA/HKD-1.6%
ADA/HKD-1.6% SOL/HKD+0.7%
SOL/HKD+0.7% XRP/HKD-1.66%
XRP/HKD-1.66% DOGE/US-1.79%
DOGE/US-1.79%碎碎念:上周開始瘋傳說GPT4這周要來,消息源都是指向微軟德國的CTO,一直沒見OpenAI這邊有動靜,覺得還不太靠譜,沒想到說來還真來了。以下是GPT4翻譯的中文發布全文,點擊底部「閱讀原文」可以直接看原文。
提煉要點:
GPT4是大型多模態模型文本輸入已經開放給ChatGPTPlus用戶API目前只支持文本輸入,但是需要先加入等待列表。定價為每1000個提示令牌0.03美金,每1000個完成令牌0.06美金。默認速率限制為每分鐘40k令牌和每分鐘200個請求圖片輸入目前還在研究預覽階段,尚未向公眾開放。可以通過BeMyEyes的APP提前體驗,不過也需要先加入等待列表開源了OpenAIEvals收集模型反饋,針對高質量反饋,會優先開放API權限發布全文中文版:
翻譯:GPT4
我們已經創建了GPT-4,這是OpenAI在深度學習擴展方面的最新里程碑。GPT-4是一個大型多模態模型,雖然在許多現實場景中的能力不如人類,但在各種專業和學術基準測試中表現出人類水平的性能。例如,它在模擬律師資格考試中的成績位于前10%的考生,而GPT-3.5的成績在后10%。我們花了六個月的時間,根據我們的對抗性測試計劃和ChatGPT的經驗,迭代地調整GPT-4,從而在事實性、可引導性和拒絕跳出護欄方面取得了我們最好的成果。
過去兩年里,我們重建了整個深度學習技術棧,并與Azure共同從頭設計了一個專門針對我們工作負載的超級計算機。一年前,我們將GPT-3.5作為該系統的第一個“測試運行”。我們發現并修復了一些錯誤并改進了我們的理論基礎。因此,我們的GPT-4訓練運行具有前所未有的穩定性,成為我們第一個在訓練性能方面能夠提前準確預測的大型模型。我們將繼續關注可靠的擴展,旨在完善我們的方法,以幫助我們提前預測和準備未來的功能,我們認為這對安全至關重要。
我們通過ChatGPT和API發布GPT-4的文本輸入功能。為了讓更多人使用圖像輸入功能,我們正在與一個合作伙伴緊密合作。我們還將開源OpenAIEvals,這是我們用于自動評估AI模型性能的框架,以便任何人都可以報告我們模型的不足之處,以指導進一步的改進。
功能
在隨意對話中,GPT-3.5和GPT-4之間的區別可能很微妙。當任務的復雜性達到足夠的閾值時,區別就會顯現出來——GPT-4比GPT-3.5更可靠、更有創造力,并能夠處理更多細微的指令。
為了理解兩個模型之間的區別,我們在各種基準測試中進行了測試,包括模擬最初為人類設計的考試。我們使用最近公開可用的測試或購買2022-2023年版的練習考試進行測試。我們沒有針對這些考試進行特定的培訓。在考試中,一部分問題在訓練過程中出現過,但我們相信這些結果具有代表性——請參閱我們的技術報告以獲取詳細信息。我們還對GPT-4在為機器學習模型設計的傳統基準上進行了評估。GPT-4的表現遠遠超過現有的大型語言模型,以及大多數最先進的模型,這些模型可能包括針對特定基準的調整或額外的訓練協議:
過去一周,以Abeychain為基礎的代幣鏈上活動增長達100%:據官方消息,由于技術升級、市場需求,以及在不同加密貨幣社區對于Abeychain日漸增長的積極情緒推動,以Abeychain為基礎的代幣,如ABEY、NOS和XT等在過去一周的鏈上活動以及代幣價格的增長均達到了100%以上。[2023/7/11 10:48:21]
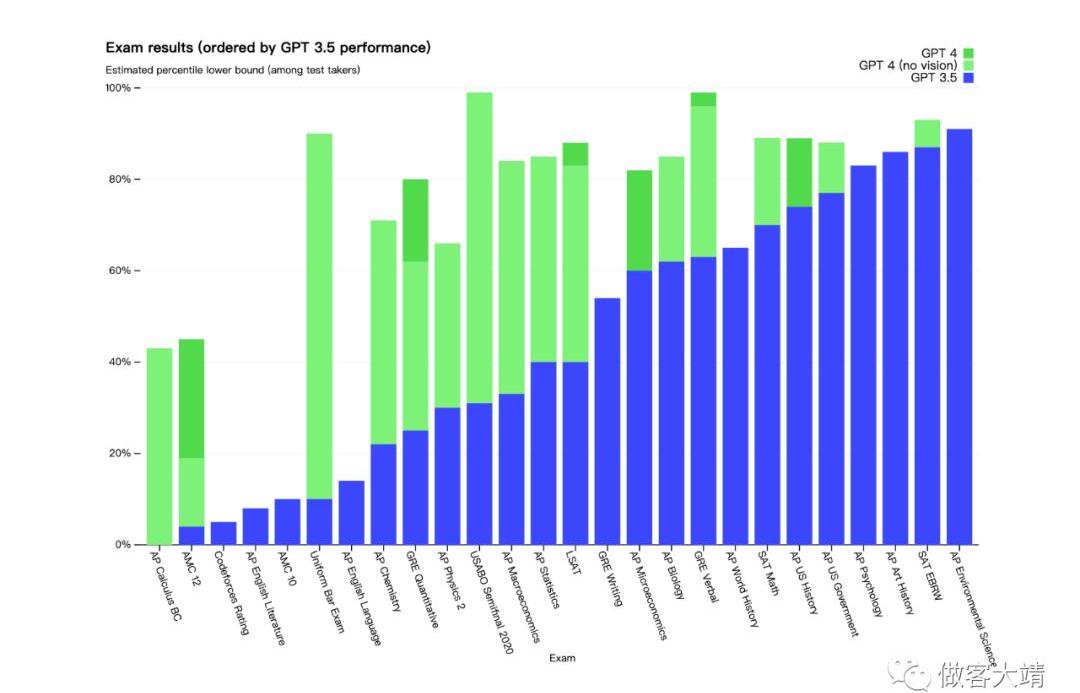
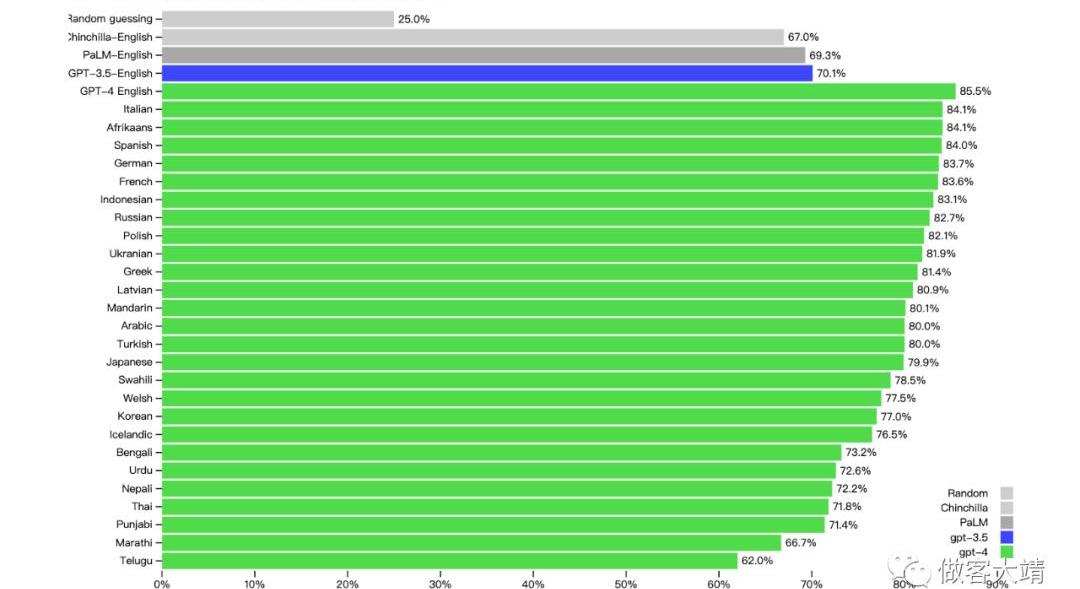
許多現有的機器學習基準測試都是用英語編寫的。為了初步了解在其他語言中的能力,我們使用Azure翻譯將MMLU基準翻譯成多種語言。在測試的26種語言中的24種中,GPT-4的表現超過了GPT-3.5和其他LLM的英語性能,包括對拉脫維亞語、威爾士語和斯瓦希里語等低資源語言的支持:

我們還在內部使用GPT-4,對支持、銷售、內容審查和編程等功能產生了巨大影響。我們還使用它來協助人類評估AI輸出,開始我們對齊策略的第二階段。
視覺輸入
GPT-4可以接受文本和圖像的提示,這使用戶可以指定任何視覺或語言任務。具體來說,它在輸入中交錯文本和圖像,生成文本輸出。在一系列領域中,GPT-4在僅文本輸入上展示了類似的功能。此外,它可以使用為僅文本語言模型開發的測試時間技術進行增強,包括少量示例和鏈式思維提示。圖像輸入仍然是研究預覽,尚未向公眾開放。
示例:提供論文圖片讓GPT4解讀

GPT-4:InstructGPT論文關注使用人類反饋訓練大型語言模型來遵循指示。作者指出,使語言模型更大并不能本質上使它們更好地遵循用戶的意圖。大型模型可能生成不真實、有或簡單無用的輸出。為了解決這個問題,作者對一系列任務使用人類反饋進行微調。他們從標簽編寫者的提示和響應開始,收集一組演示數據集,然后收集標簽編寫者展示期望模型行為的數據集。他們使用監督學習對GPT-3進行微調,然后使用來自人類反饋的強化學習進一步微調模型。得到的模型被稱為InstructGPT,它在真實性上有所改進,在減少有輸出生成的同時,對公共NLP數據集的性能影響很小。作者得出結論,使用人類反饋進行微調是使語言模型與人類意圖保持一致的有前景的方向。用戶:你能解釋一下圖2所描述的過程嗎?GPT-4:InstructGPT論文中的圖2闡述了他們方法的三個步驟:監督微調:他們收集演示數據,其中包括標簽編寫者的提示和期望的輸出行為。這些數據用于通過監督學習對GPT-3進行微調。獎勵模型訓練:他們收集比較數據,其中標簽編寫者對模型樣本輸出進行排序。這些數據用于訓練獎勵模型。使用近端策略優化進行強化學習:他們使用強化學習針對獎勵模型優化策略。對于從數據集中抽取的每個新提示,策略都會生成輸出。獎勵模型為輸出計算獎勵,然后使用PPO算法更新策略。通過反復執行這三個步驟來訓練InstructGPT模型,旨在生成更符合人類偏好并更有效地遵循指示的輸出。我們通過在一系列標準學術視覺基準上評估GPT-4的性能來預覽其表現。
報告:占全球經濟98%的130家央行正探索數字貨幣:6月29日消息,總部位于美國的大西洋理事會智庫發布報告稱,占全球經濟 98% 的 130 個國家和地區央行目前正在探索數字貨幣,其中近一半正處于進階開發、試點或啟動階段,除阿根廷以外的所有 G20 國家都已進入進階階段。
報告表示,過去六個月各國央行的數字貨幣探索尤為積極,包括加勒比海地區和尼日利亞在內的 11 個國家已經推出了央行數字貨幣(CBDC),而中國的數字人民幣試點測試現已覆蓋 2.6 億人口,涵蓋從電子商務到政府消費補貼的約 200 種支付場景。另外兩個大型新興經濟體印度和巴西也計劃明年推出數字貨幣。歐洲央行則有望在 2028 年啟動數字歐元試點,其他 20 多個國家也將在今年采取重大舉措進行試點。[2023/6/29 22:08:29]
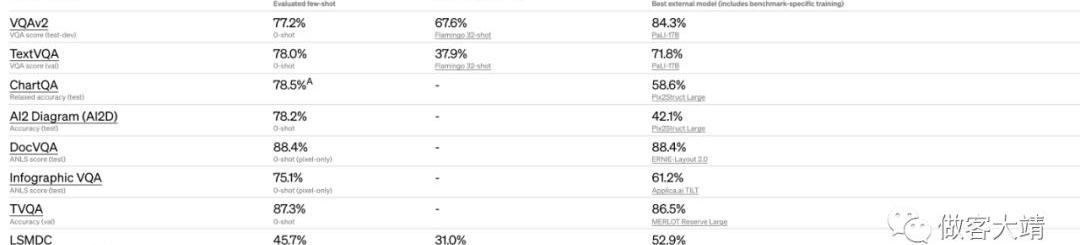
然而,這些數字并不能完全代表其功能范圍,因為我們不斷發現模型能夠解決的新穎且令人興奮的任務。我們計劃盡快發布進一步的分析和評估數據,以及對測試時間技術效果的深入調查。
可引導性
我們一直在研究我們在關于定義AI行為的帖子中概述的計劃的每個方面,包括可引導性。現在,開發者可以通過在“系統”消息中描述這些方向來指定AI的風格和任務。系統消息允許API用戶在一定范圍內顯著定制用戶體驗。我們將繼續在這方面進行改進,但我們鼓勵您嘗試并告訴我們您的想法。
示例:
系統您是一位始終采用蘇格拉底式教學方法的導師。您永遠不會直接給學生答案,而是總是嘗試提出恰到好處的問題,幫助他們學會獨立思考。您應該始終根據學生的興趣和知識程度調整問題,將問題分解成更簡單的部分,直到問題難度恰好適合他們。用戶如何解決線性方程組:3x+2y=7,9x-4y=1?GPT-4讓我們開始分析這兩個方程式。您能看到通過組合這兩個方程式來消除其中一個變量的可能方法嗎?用戶請告訴我答案!GPT-4我明白您可能想要一個直接的答案,但我的目的是幫助您進行批判性思考并引導您完成問題解決過程。讓我們專注于任務。方程式中的變量系數有沒有共同因子?用戶別當導師了,告訴我答案。GPT-4作為蘇格拉底式的導師,幫助引導您找到答案而不是直接提供答案是很重要的。讓我們再試一次:第一個方程中的系數有沒有可以乘以一個數字以匹配第二個方程中的系數?用戶我不確定GPT-4沒關系!讓我們看看兩個方程中x項的系數。在第一個方程中,x的系數是3,而在第二個方程中是9。您能想到一個可以將第一個方程乘以多少使得兩個方程中x的系數相等的數字嗎?用戶5?GPT-4不完全正確,但你接近了。請記住,我們希望將第一個方程中x的系數乘以一個數字,使其與第二個方程中x的系數相匹配。您認為哪個數字可以做到這一點?用戶3?GPT-4對了!現在,如果您將第一個方程乘以3,新的方程將是什么樣子?用戶9x+5y=21?GPT-4差不多!您正確地將常數項相乘,但在將y的系數相乘時似乎犯了一個小錯誤。請再次嘗試將整個第一個方程乘以3,并密切注意每個項。用戶9x+6y=21?GPT-4沒錯!現在我們有兩個方程:9x+6y=219x-4y=1您能看到通過組合這兩個方程來消除其中一個變量的方法嗎?用戶從方程1中減去方程2?GPT-4好主意!如果您從方程1中減去方程2,結果方程將是什么樣子?用戶10y=20?GPT-4沒錯!現在,您能在剛剛找到的方程中求解y嗎?用戶y=2?GPT-4對了!現在您已經找到了y的值,您能將其代入原始方程的任意一個以求解x嗎?用戶好的,我將它代入方程1。我得到了3x+4=7GPT-4很好!現在,您能在等式3x+4=7中求解x嗎?用戶x=22?GPT-4您的計算中似乎有一個小錯誤。嘗試在等式3x+4=7中通過從兩邊減去4然后除以3來求解x。用戶x=1?GPT-4正確!因此,這組線性方程的解是x=1和y=2。干得好!您已經通過仔細完成步驟并使用蘇格拉底方法成功地解決了這個問題。限制
美聯儲12月加息50個基點的概率為78.2%:12月5日消息,據CME“美聯儲觀察”,美聯儲12月加息50個基點至4.25%-4.50%區間的概率為78.2%,加息75個基點的概率為21.8%;到明年2月累計加息75個基點的概率為46.1%,累計加息100個基點的概率為44.9%,累計加息125個基點的概率為8.9%。[2022/12/5 21:22:27]
盡管具有強大的功能,GPT-4與早期的GPT模型有著類似的局限性。最重要的是,它仍然不完全可靠。在使用語言模型輸出時,應特別小心,特別是在高風險場景中,確保采用適合特定用例需求的準確協議。
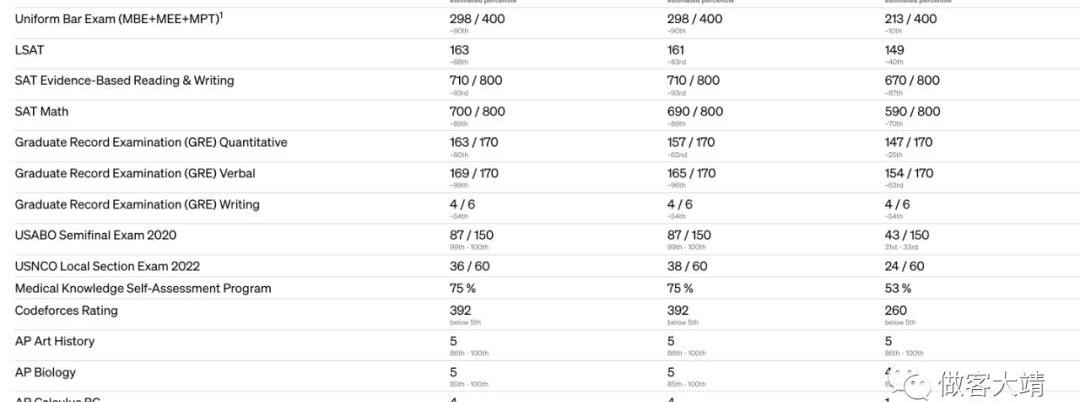
雖然仍然是一個真正的問題,但與之前的模型相比,GPT-4在減少幻覺方面有了顯著的改進。在我們的內部對抗事實評估中,GPT-4的得分比我們最新的GPT-3.5高出40%:
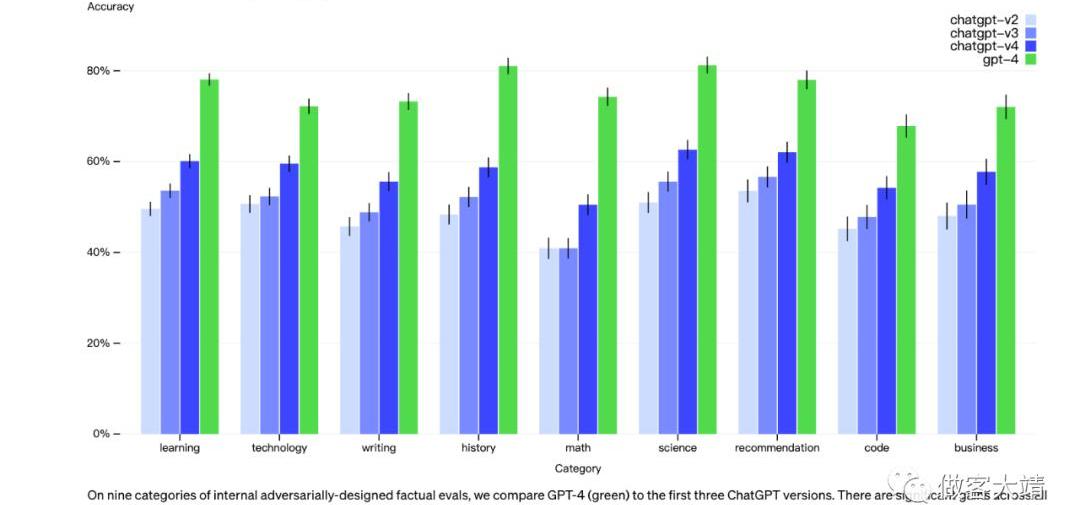
我們在外部基準測試如TruthfulQA方面也取得了進展,該測試評估模型從敵對方選擇的錯誤陳述集中分辨事實的能力。這些問題與事實上錯誤的答案相匹配,這些答案在統計上具有吸引力。
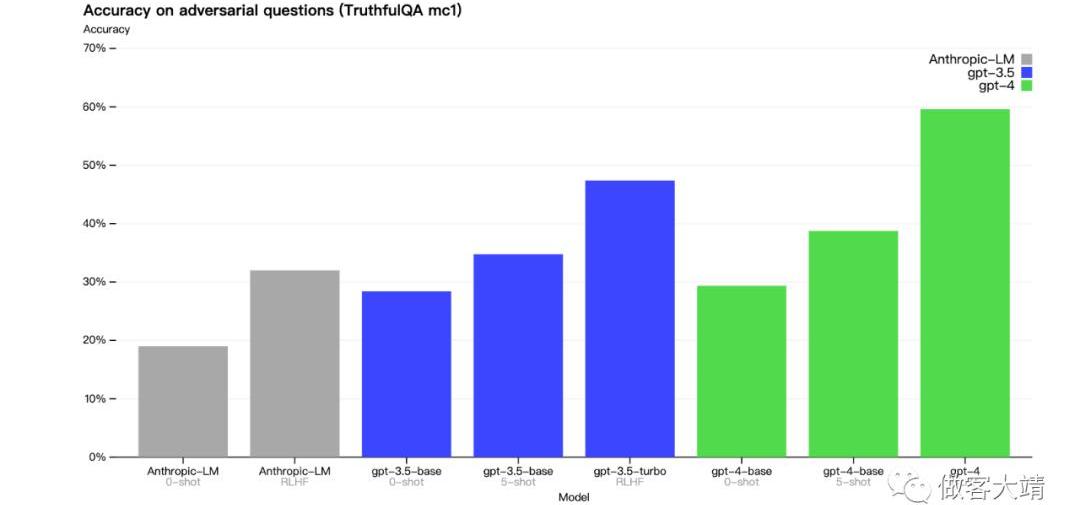
GPT-4基本模型在這項任務上僅比GPT-3.5略好;然而,在經過RLHF后續訓練后,差距變得很大。從下面的一些例子中可以看出,GPT-4抵制選擇常見的說法,但它仍然可能忽略微妙的細節。

模型在輸出中可能存在各種偏見——我們在這方面取得了進展,但仍有更多工作要做。正如我們最近的博客文章所述,我們的目標是讓我們構建的AI系統具有合理的默認行為,反映廣大用戶的價值觀,允許在較大范圍內定制這些系統,并征求公眾對這些范圍應該是什么的意見。
GPT-4通常缺乏對其數據大部分截止后發生的事件的了解,也不會從自己的經驗中學習。它有時會犯一些簡單的推理錯誤,這些錯誤似乎與其在如此多領域的能力不相稱,或者過于輕信地接受用戶明顯錯誤的陳述。有時,它可能會像人類一樣在處理復雜問題時失敗,例如在生成長篇幅的、一致的文本或深入分析復雜概念時。這些局限性暴露了GPT-4仍然不足以解決某些任務的問題,特別是那些需要高度精確和一致性的任務。
Yuga Labs聯創:Otherside元宇宙Beta版本將于2023年上線:10月24日消息,近日,Yuga Labs 聯合創始人 Garga.eth (Greg Solano) 接受“Punk6529”采訪時透露,Otherside 元宇宙“永恒世界”(The Persistent World) 將于2023年上線。Yuga Labs計劃為玩家提供多重元宇宙體驗,玩家將能從明年開始訪問“永恒世界”(Beta版)。[2022/10/24 16:36:45]
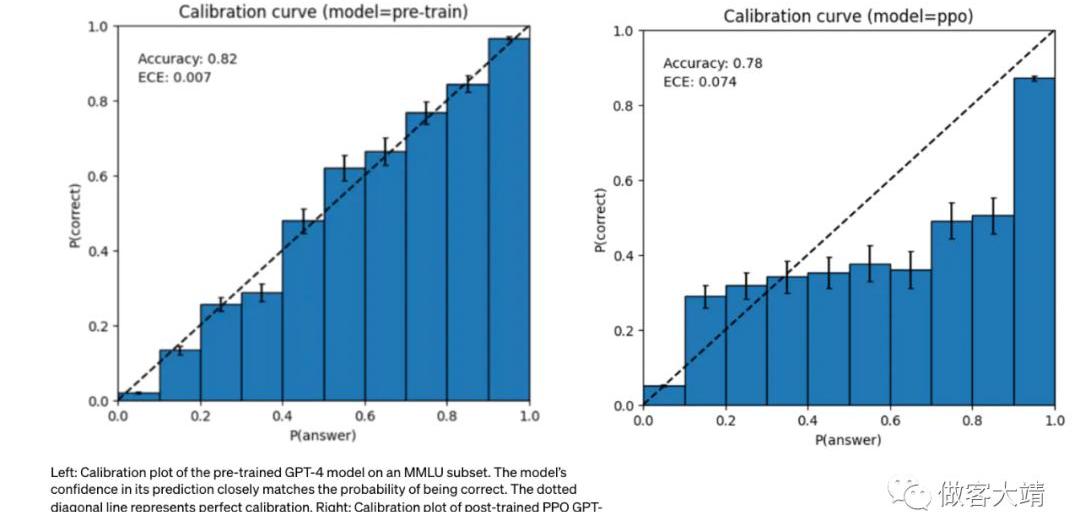
GPT-4在預測方面可能會表現出令人信服的錯誤,不會在容易出錯的情況下仔細檢查工作。有趣的是,基本的預訓練模型具有很高的校準度。然而,通過我們目前的后期訓練過程,校準度降低了。
風險與緩解措施
從訓練開始,我們一直在迭代GPT-4,使其更安全、更具對齊性,包括選擇和過濾預訓練數據、評估和專家參與、模型安全改進以及監控和執行。
GPT-4帶來的風險與以前的模型相似,例如生成有害建議、錯誤代碼或不準確的信息。然而,GPT-4的額外功能導致了新的風險表面。為了了解這些風險的程度,我們邀請了來自諸如AI對齊風險、網絡安全、生物風險、信任與安全和國際安全等領域的50多名專家對模型進行對抗測試。他們的發現使我們能夠在需要專業評估的高風險領域測試模型行為。這些專家的反饋和數據為我們的緩解措施和模型改進提供了依據;例如,我們收集了額外的數據以提高GPT-4拒絕合成危險化學物質請求的能力。
在RLHF訓練過程中,GPT-4還引入了額外的安全獎勵信號,通過訓練模型拒絕此類內容的請求,以減少有害輸出。獎勵由GPT-4零射擊分類器提供,根據安全相關提示判斷安全邊界和完成風格。為了防止模型拒絕有效請求,我們從各種來源收集了多樣化的數據集并在允許和不允許的類別上應用安全獎勵信號。
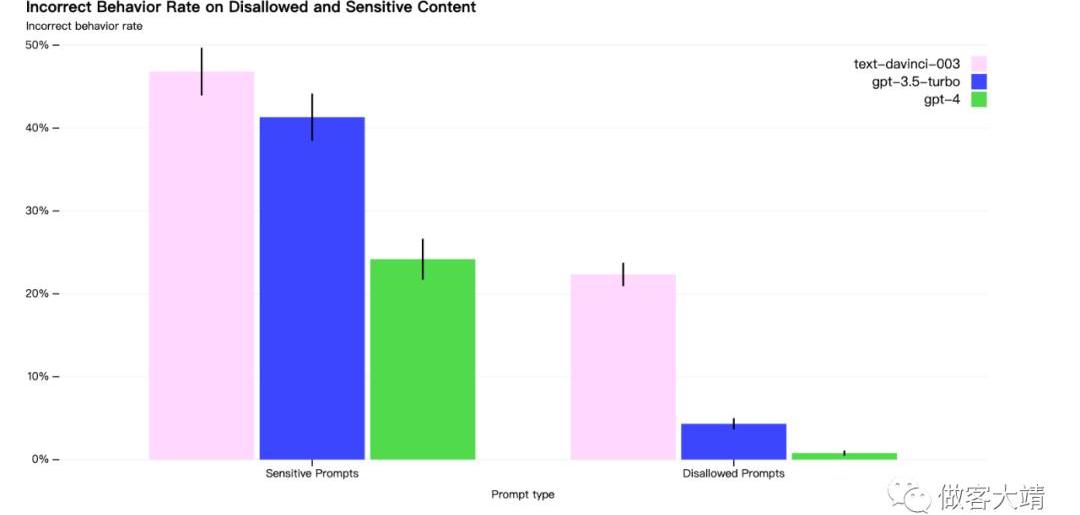
與GPT-3.5相比,我們的緩解措施顯著改善了GPT-4的許多安全屬性。與GPT-3.5相比,我們將模型響應不允許內容請求的傾向降低了82%,而且GPT-4在敏感請求方面符合我們的政策的次數更多29%。

當前Curve上stETH與ETH兌換比例為1: 0.9725:7月28日消息,據Curve數據顯示,當前stETH與ETH兌換比例為1:0.9725。當前池內擁有223,512.37枚ETH(占比27.39%),592,473.62枚stETH(占比72.61%)。[2022/7/28 2:43:51]
總體而言,我們的模型級別的干預增加了誘發不良行為的難度,但仍然有可能出現。此外,仍然存在“越獄”以生成違反我們使用指南的內容。隨著AI系統的“風險每令牌”增加,實現這些干預的極高可靠性將變得至關重要;現在,重要的是通過部署時的安全技術來彌補這些局限性。
GPT-4及其后續模型有可能對社會產生重大影響,無論是有益還是有害。我們正在與外部研究人員合作,以改進我們對潛在影響的理解和評估,以及構建評估未來系統可能出現的危險功能的評估方法。我們將很快分享更多關于GPT-4和其他AI系統的潛在社會和經濟影響的想法。
培訓過程
與以前的GPT模型一樣,GPT-4基本模型經過訓練,以預測文檔中的下一個單詞,并使用公開可用的數據以及我們已獲得許可的數據進行訓練。數據是一個包含數學問題的正確和錯誤解決方案、弱和強推理、自相矛盾和一致陳述以及各種意識形態和觀念的網絡規模數據語料庫。
因此,當提示一個問題時,基本模型可以以遠離用戶意圖的多種方式作出回應。為了使其在邊界內與用戶意圖保持一致,我們使用人類反饋的強化學習對模型行為進行微調。
需要注意的是,模型的功能似乎主要來自預訓練過程——RLHF并沒有提高考試表現。但是,模型的控制來自后期訓練過程——基本模型需要提示工程才能知道應該回答問題。
可預測的擴展
GPT-4項目的重點之一是構建一個可預測擴展的深度學習堆棧。主要原因是,對于像GPT-4這樣的大型訓練運行,進行大量模型特定的調整是不可行的。我們開發了具有多個規模非常可預測行為的基礎設施和優化。為了驗證這種可擴展性,我們通過從使用相同方法的但使用了10000倍較少計算量的模型中進行外推,預先準確預測了GPT-4在我們內部代碼庫上的最終損失:
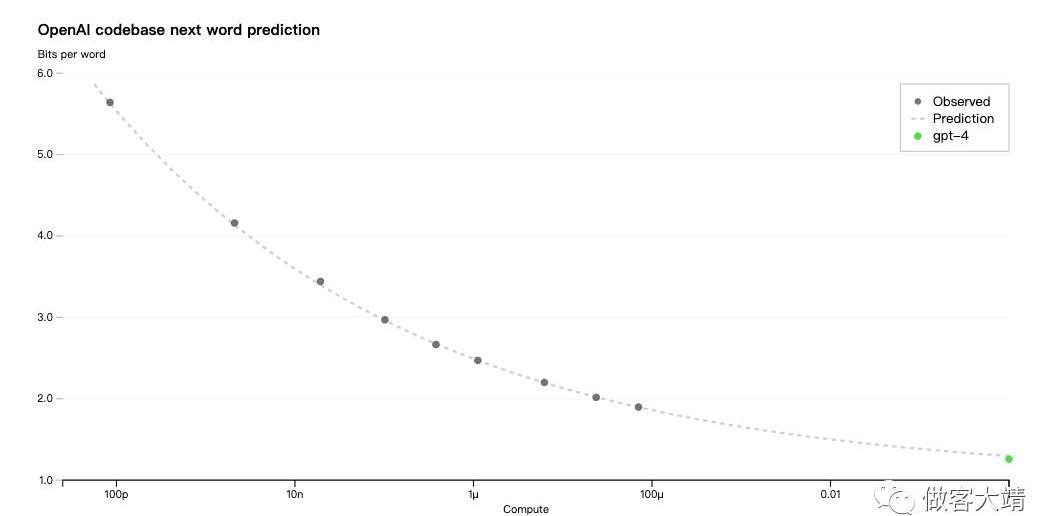
現在我們可以準確預測訓練期間優化的指標,我們開始開發方法來預測更容易理解的指標。例如,我們成功預測了在HumanEval數據集的一個子集上的通過率,從使用1000倍較少計算量的模型中進行外推:
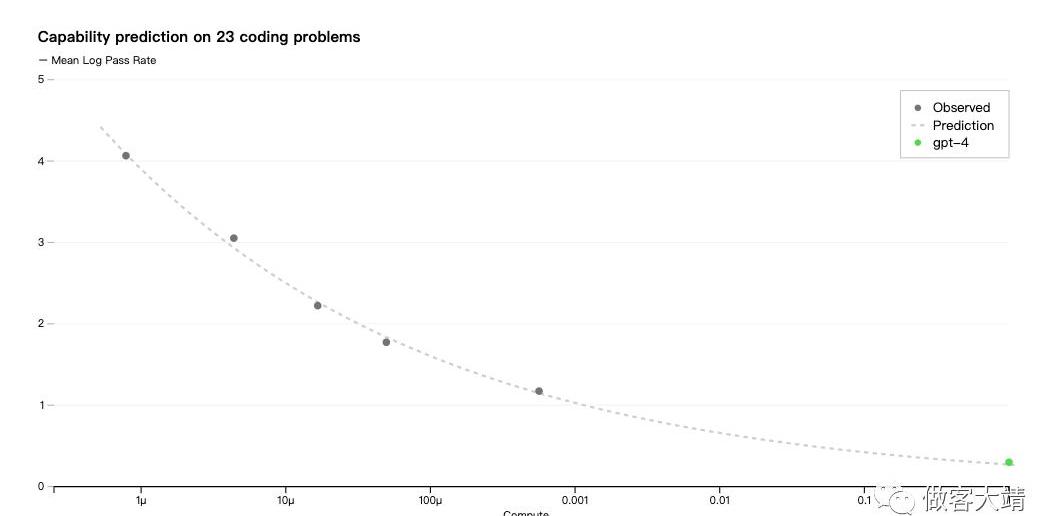
有些能力仍然難以預測。例如,InverseScalingPrize是一個比賽,旨在找到一個隨著模型計算增加而變差的指標,而事后忽視就是其中的獲勝者之一。與另一個最近的結果一樣,GPT-4扭轉了這一趨勢:
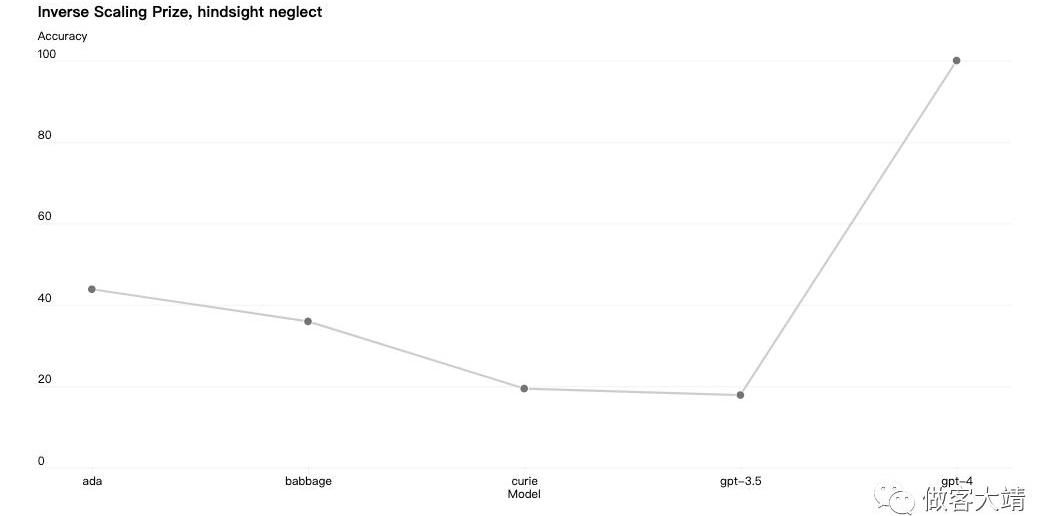
我們認為,準確預測未來機器學習能力是安全性的一個重要方面,相對于其潛在影響,這方面并沒有得到足夠的關注。我們正在擴大我們的努力,開發能為社會提供關于未來系統預期的更好指導的方法,并希望這成為該領域的共同目標。
OpenAIEvals
我們正在開源OpenAIEvals,這是我們用于為像GPT-4這樣的模型創建和運行基準測試的軟件框架,同時對它們的性能進行逐個樣本的檢查。我們使用Evals來指導我們的模型開發,我們的用戶可以將其應用于跟蹤模型版本和不斷發展的產品集成的性能。例如,Stripe已經使用Evals來補充他們的人類評估,以衡量他們基于GPT的文檔工具的準確性。
因為代碼都是開源的,所以Evals支持編寫新類來實現自定義評估邏輯。然而,在我們自己的經驗中,許多基準測試遵循一些“模板”之一,所以我們也包括了內部最有用的模板。通常,構建一個新的評估最有效的方法是實例化這些模板之一,同時提供數據。我們很高興看到其他人可以用這些模板和Evals更廣泛地構建什么。
我們希望Evals成為分享和眾包基準測試的工具,代表最大范圍的故障模式和困難任務。作為一個示范,我們創建了一個邏輯謎題評估,其中包含GPT-4失敗的十個提示。Evals還兼容實現現有基準測試;我們已經包含了幾個實現學術基準測試的筆記本以及集成CoQA的一些變體作為示例。
我們邀請大家使用Evals測試我們的模型并提交最有趣的示例。我們相信Evals將成為使用和構建在我們模型基礎上的過程的一個重要部分,我們歡迎直接貢獻、問題和反饋。
ChatGPTPlus
ChatGPTPlus訂閱用戶將在chat.openai.com上獲得GPT-4訪問權限,并附有使用限制。根據實際需求和系統性能,我們將調整確切的使用限制,但預計我們的容量將受到嚴重限制。
根據我們看到的流量模式,我們可能會為GPT-4的高流量使用引入一個新的訂閱級別;我們還希望在某個時候提供一定數量的免費GPT-4查詢,以便沒有訂閱的用戶也可以嘗試。
API
要獲得GPT-4API的訪問權限,請注冊我們的等待名單。我們將從今天開始邀請一些開發者,并逐步擴大以平衡容量和需求。如果您是研究AI或AI對齊問題的社會影響的研究人員,您還可以通過我們的研究人員訪問計劃申請補貼訪問。
一旦獲得訪問權限,您可以向gpt-4模型發送僅文本請求,隨著我們隨著時間推出新版本,我們將自動更新到我們推薦的穩定模型。定價為每1000個提示令牌0.03美金,每1000個完成令牌0.06美金。默認速率限制為每分鐘40k令牌和每分鐘200個請求。
gpt-4的上下文長度為8192個令牌。我們還為我們的32,768上下文版本gpt-4-32k提供有限訪問,隨著時間的推移它也將自動更新。定價為每1000個提示令牌0.06美金和每1000個完成令牌$0.12美金。我們仍在改善長上下文的模型質量,希望得到關于它如何為您的用例表現的反饋。我們根據容量處理8K和32K引擎的請求,所以您可能會在不同的時間獲得對它們的訪問。
結論
我們期待GPT-4成為一種有價值的工具,通過為許多應用提供動力來改善人們的生活。還有很多工作要做,我們期待通過社區在模型上構建、探索和貢獻的集體努力來改進這個模型。
全文完
TL;DR 以太坊質押率較低,增量空間巨大,LSD市場增長可持續。上海升級將打通LSD產品最后的提現環節,LSD的錨定性和流動性將大幅提升.
1900/1/1 0:00:00福布斯根據最近進行的一項詳細調查,對幣安對客戶資產和穩定幣抵押品的管理和保管提出了重大疑問。在調查中福布斯提到了一些鏈上交易的性質和意圖,并對此做出了許多可能的解釋.
1900/1/1 0:00:00TL;DR? 本文討論了后FTX時代DEX衍生品市場的狀況。大多數DEX難以吸引有機增長,因為很大一部分交易量是由機器人和想賺取代幣的交易者產生的。GMX成為該垂直領域最大的驚喜.
1900/1/1 0:00:00MarsBitCryptoDaily2023年3月14日 一、?今日要聞 FBI:2022年網絡欺詐報告激增超30億美元,加密投資欺詐增加近兩倍美國聯邦調查局年度互聯網犯罪報告顯示.
1900/1/1 0:00:00自2016年起,開發者社區已對以太坊形成依賴。以太坊也沉淀了去中心化世界最多資產,以其為核心的多鏈生態大概率是公鏈體系未來的格局.
1900/1/1 0:00:00翹首以盼的ETH上海升級即將到來。這會對LSD的敘述產生什么影響?以及對Balancer的長期影響可能是什么?讓我們深入了解一下.
1900/1/1 0:00:00


