






 BTC/HKD-0.91%
BTC/HKD-0.91% ETH/HKD-1.72%
ETH/HKD-1.72% LTC/HKD-1.57%
LTC/HKD-1.57% DOT/HKD-1.71%
DOT/HKD-1.71% ADA/HKD-2.18%
ADA/HKD-2.18% SOL/HKD-2.31%
SOL/HKD-2.31% XRP/HKD-3.12%
XRP/HKD-3.12% DOGE/US-2.99%
DOGE/US-2.99%2020年4月9日,中共中央、國務院發布《關于構建更加完善的要素市場化配置體制機制的意見》,首次將數據與土地、勞動力、資本、技術等傳統要素并列為要素之一,提出要加快培育數據要素市場,包括推進政府數據開放共享、提升社會數據資源價值和加強數據資源整合和安全保護等三方面工作。
數據作為要素是一個新命題,有大量前沿問題需要研究。在文獻中,相關問題歸屬于數據經濟范疇。數據經濟指數據收集、組織、使用、分享、流轉和管理等活動組成的經濟生態。
德勤和阿里研究院認為數據資產不完全符合會計準則中對于“資產”及“無形資產”的定義。劍橋大學研究報告《數據的價值》對數據經濟的理論、實踐和政策問題進行了全面綜述。李小加提出組建數據要素產業化聯盟,梳理數據經濟中八方面的重要問題。于施洋等分析了我國深化數據要素市場化配置面臨的挑戰,提出搭建公共平臺、完善市場條件、研究配套政策、推動協同聯動、優化市場結構等方面政策建議。但從國內外研究來看,數據經濟是一個方興未艾的領域,而且學術研究略顯落后于行業和監管實踐,有不少新概念、新問題和新機制值得梳理。
本文對以下三個問題進行了初步探討:第一,數據要素有哪些重要的技術和經濟學特征?第二,數據價值的內涵和計量方法;第三,數據要素的配置機制。
一、數據要素的技術和經濟學特征
數據的技術特征
什么是數據?與通常認為的不同,這是信息科學中一個基本但復雜的問題,沒有顯而易見的答案。對數據的理解離不開對信息和知識等相關概念的辨析。Ackoff提出了DIKW模型,D指數據,I指信息,K指知識,W指智慧。DIKW模型在信息管理、信息系統和知識管理等領域有廣泛使用,不同研究者從不同角度給出不同解釋,Rowley進行了綜述。本文不深入討論DIKW模型,只在Rowley的基礎上梳理數據的技術特征中與經濟學分析最相關的部分。
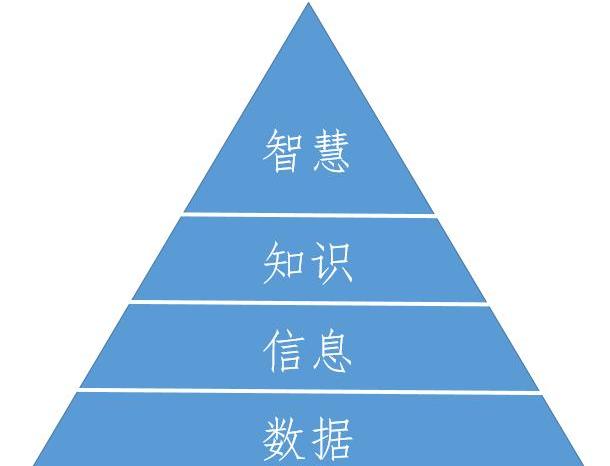
圖1:DIKW模型
第一,智慧、知識、信息和數據之間依次存在從窄口徑到寬口徑的從屬關系。從數據中可以提取出信息,從信息中可以總結出知識,從知識中可以升華出智慧。這些提取、總結和升華都不是簡單的機械過程,依靠不同方法論和額外輸入。因此,信息、知識和智慧盡管也屬于數據的范疇,卻是“更高階”的數據。
第二,數據是觀察的產物。觀察對象包括物體、個人、機構、事件以及它們所處環境等。觀察是基于一系列視角、方法和工具進行的,并伴隨著相應的符號表達系統,比如度量衡單位。數據就是用這些符號表達系統記錄觀察對象特征和行為的產物。數據可以采取文字、數字、圖表、聲音和視頻等形式。在存在形態上,數據有數字化的,也有非數字化的。但隨著信息和通訊技術的發展,越來越多數據被數字化,在底層都表示成二進制。
第三,數據經過認知過程處理后得到信息,給出關于誰、什么、何處和何時等問題的答案。信息是有組織和結構化的數據,與特定目標和情景有關,因此有價值和意義。比如,根據信息論,信息能削減用熵度量的不確定性。
第四,與數據和信息相比,知識和智慧更難被準確定義。知識是對數據和信息的應用,給出關于如何做的答案。智慧則有鮮明的價值判斷意味,在很多場合與對未來的預測和價值取向有關。
接下來用計量經濟學為例說明DIKW模型。計量經濟學是經濟學實證分析的主要方法。實證分析基于觀察,回答“是什么”的問題。在計量經濟學中,觀察的對象通常被稱為樣本,可以是個人、機構、地區甚至國家。從不同角度觀察樣本,對應計量經濟學中的變量概念。從不同角度觀察一組樣本得到橫截面數據,而在不同時點上持續從同一角度觀察得到時間序列數據,橫截面數據和時間序列數據的綜合則是面板數據。這些類型的數據都是結構化數據。隨著越來越多的數據被數字化,以及人工智能和大數據分析方法的發展,半結構化數據和非結構化數據在經濟學中也有越來越多應用,比如互聯網瀏覽、點擊等數據。
計量經濟學從數據中提煉信息,主要包括:一是發現數據中隱含的規律和模式;二是估計模型;三是檢驗假說。這對應著DIKW模型的信息層次。比如,對數據做描述統計,計算變量的平均值、標準差以及變量之間的相關系數等,是從數據中提煉信息的最簡單方式之一。計量經濟學經常假設數據遵循數據生成過程,但數據生成過程的模型形式和參數取值未知,并且隨機干擾會為觀察帶來誤差。計量經濟學根據觀察到的數據,估計數據生成過程,再據此檢驗假說。人工智能和大數據分析方法對數據的處理更為靈活,分為預測型分析和描述型分析。預測型分析是根據某些變量的取值,預測另外一些變量的取值。描述型分析是導出、概括數據中潛在聯系的模式,包括相關、趨勢、聚類、軌跡和異常等。兩類分析體現為分類、回歸、關聯分析、聚類分析、推薦系統和異常檢測等具體方法。
新一屆美國眾議院金融服務委員會主席:有必要“將個人不良行為與加密行業創新區分開”:金色財經報道,在FTX事件之后,新一屆美國眾議院金融服務委員會主席帕特里克·麥克亨利表示,有必要“將個人的不良行為與加密行業創新創造的利益區分開” ,此前SBF在華盛頓的游說團體致力于美國國會通過一項賦予美國商品期貨交易委員會 (CFTC) 監管加密貨幣權力的法案,預計將被納入 2023 年的預算支出方案,但由于過去幾周的事態發展,現在已不太可能推進。此外,美國國會區塊鏈核心小組成員的眾議員 Jake Auchincloss 指出,與2014年時的加密行業不同,現在是區塊鏈投資者和企業家需要重新建立信譽的時候。(Cointelegraph)[2023/1/1 22:19:41]
根據計量經濟學分析結果提出政策建議,對應著DIKW模型的知識層次。很多政策研究屬于規范分析,回答“應該是什么”的問題。經濟學關于經濟均衡、經濟增長、宏觀調控、價格機制、微觀激勵和風險定價等方面的洞見,對應著DIKW模型的智慧層次。
一般而言,數據的技術特征主要包括以下維度:
數據的樣本分布、時間覆蓋和變量/屬性/字段等。
數據容量,比如樣本數、變量數、時間序列長度和占用的存儲空間等。
數據質量,比如樣本是否有代表性,數據是否符合事先定義的規范和標準,觀察的顆粒度、精度和誤差,以及數據完整性。
數據的時效性。鑒于觀察對象的特征和行為可以隨時間變化,數據是否還能反映觀察對象的情況?
數據來源。有些數據來自第一手觀察,有些數據由第一手觀察者提供,還有些數據從其它數據推導而來。數據可以來自受控實驗和抽樣調查,也可以來自互聯網、社交網絡、物聯網和工業互聯網等。數據可以由人產生,也可以由機器產生。數據可以來自線上,也可以來自線下。
數據類型,包括是數字化還是非數字化的,是結構化還是非結構化的,以及存在形式。
不同數據集之間的互操作性和可聯接性,比如樣本ID是否統一,變量定義是否一致,以及數據單位是否一致等。
是否為個人數據。個人數據在隱私保護上有很多特殊性,需要專門討論。
數據的經濟學特征
與數據的技術特征相比,數據的經濟學特征要復雜得多。數據可以產生價值,因此具有資產屬性。數據兼有商品和服務的特征。一方面,數據可存儲、可轉移,類似商品。數據可積累,在物理上不會消減或腐化。另一方面,很多數據是無形的,類似服務。數據作為資產具有很多特殊性,可以從表1的視角分析:

表1:公共產品、準公共產品和私人產品的分類
非競爭性指的是,當一個人消費某種產品時,不會減少或限制其他人對該產品的消費。換言之,該產品每增加一個消費者,所帶來的邊際成本等于0。大部分數據可以被重復使用,重復使用不會降低數據質量或容量,并且可以被不同人在同一時間使用,因此具有非競爭性。
非排他性指的是,當某人在付費消費某種產品時,不能排除其他沒有付費的人消費這一產品,或者排除的成本很高。很多數據是非排他性的,比如天氣預報數據。但通過技術和制度設計,有些類型的數據有排他性。比如,一些媒體信息終端采取付費形式,只有付費會員才可以閱讀。
根據表1,很多數據屬于公共產品,可以由任何人為任何目的而自由使用、改造和分享。比如,政府發布的經濟統計數據和天氣預報數據。一些數據是俱樂部產品,屬于準公共產品,比如前面提到的收費媒體信息終端。大部分數據是非競爭性的,因此屬于私人產品和公共資源的數據較少。
數據的所有權不管在法律上還是在實踐中都是一個復雜問題,特別對個人數據。數據容易在未經合理授權的情況下被收集、存儲、復制、傳播、匯集和加工,并且數據匯集和加工伴隨著新數據的產生。這使得數據的所有權很難界定清楚,也很難被有效保護。比如,在互聯網經濟中,互聯網平臺記錄下用戶的點擊、瀏覽和購物歷史等,是非常有價值的數據。這些數據盡管描述了用戶的特征和行為,但不像用戶個人身份信息那樣由用戶對外提供,很難說由用戶所有。互聯網平臺盡管記錄和存儲這些數據,但這些數據與用戶的隱私和利益息息相關,很難任由互聯網平臺在用戶不知情的情況下使用和處置這些數據,所以互聯網平臺也不擁有完整產權。
Ripple CEO:加密貨幣“部落主義”阻礙加密行業:4月20日消息,Ripple首席執行官Brad Garlinghouse表示,圍繞比特幣和其他加密貨幣的“部落主義”正在阻礙整個2萬億美元的市場。根據Garlinghouse的說法,比特幣的“極簡主義”意味著加密貨幣行業在游說美國立法者時產生了“分裂”。此外,Garlinghouse稱其持有BTC、ETH和其他加密貨幣,并表示堅信這個行業將繼續蓬勃發展。(CNBC)[2022/4/20 14:36:10]
因此,需要通過制度設計和密碼學技術等精巧界定用戶作為數據主體以及互聯網平臺作為數據控制者的權利,這會為他們之間的經濟利益關系產生顯著影響。
很多文章把數據比喻成新經濟的石油。這個比喻實際上不準確。石油是競爭性和排他性的,產權可以清楚界定,作為私人產品形成了現貨和期貨等復雜的市場交易模式。很多數據難以清晰界定所有權,作為公共產品或準公共產品難以有效參與市場交易。因此,把數據比喻成陽光更為合適。
二、數據價值的內涵和計量
數據價值的內涵
根據DIKW模型,從數據中提煉出信息、知識和智慧,這隱含著數據價值鏈的概念。原始數據經過處理并與其他數據整合后,再經分析形成可行動的洞見,最終由行動產生價值。
數據價值可以從微觀和宏觀兩個層面理解。在微觀層面,信息、知識和智慧既可以滿足使用者的好奇心,更可以提高使用者的認知,幫助他們更好做出決策,最終效果都是提高他們的效用。數據對使用者效用的提高,就反映了數據價值。在宏觀層面,信息、知識和智慧有助于提高全要素生產率,發揮乘數作用,這也是數據價值的體現。本文主要討論微觀層面的數據價值,有以下關鍵特征。
1.同樣數據對不同人的價值可以大相徑庭
第一,不同人的分析方法不一樣,從同樣數據中提煉出的信息、知識和智慧可以相差很大。比如,在科學史上,很多科學家深入研究一些大眾習以為常的現象并做出了重大發現。重物落地之于牛頓,閃電之于富蘭克林,海水的藍色之于拉曼,與它們對大眾的價值是完全不一樣的。再比如,在經濟學中,不同的經濟學家對同樣的經濟數據經常做出完全不一樣的解讀。
第二,不同人所處的場景和面臨的問題不一樣,同一數據對他們起的作用也不一樣。同一數據,對一些人可能是垃圾,對另一些人則可能是寶藏。比如,考古發現對歷史研究者的價值很大,但對金融投資者則很可能沒有價值。比如,另類數據包括個人產生數據、商業過程數據和傳感器數據等。這些數據能幫助投資者做投資決策,但對非金融投資者則沒有太大價值。不同的人可以在不同時間維度上使用數據,比如有評估過去的,有分析當前的,有預測未來的,也有做回溯測試的。使用目的不同,對數據的要求不一樣,同一數據就意味著不同價值。
第三,不同制度和政策框架對數據使用的限定不一,也會影響數據價值。換言之,數據價值內生于制度和政策。比如,不同國家對個人數據的保護程度不一,個人數據被收集和使用的情況以及產生的價值在國家之間有很大差異。我國排名靠前的互聯網平臺基于用戶行為數據推出了在線信貸產品,這在其他國家則不常見。互聯網平臺獲得用戶數據后,如果不恰當保護和使用,不尊重用戶隱私,將會影響其品牌形象和用戶信任,對數據價值和公司價值都會帶來負面影響。2020年4月,美國聯邦法院批準Facebook與美國聯邦貿易委員會就劍橋分析丑聞的50億美元和解協議。
2.數據價值隨時間變化
第一,數據有時效性。很多數據在經過一段時間后,因為不能很好反映觀察對象的當前情況,價值會下降。這種現象稱為數據折舊。數據折舊在金融市場中表現得非常明顯。比如,一個新消息在剛發布時可以對證券價格產生很大影響,但等到證券價格反映這個消息后,它對金融投資的價值就急劇降到0。在DIKW模型中,將數據提煉為信息、知識和智慧,并且提煉層次越高,就越能抵抗數據折舊。
第二,數據有期權價值。新機會和新技術會讓已有數據產生新價值。在很多場合中,收集數據不僅是為了當下的需求,也有助于提升未來的福利。
3.數據會產生外部性
第一,數據對個人的價值稱為私人價值,數據對社會的價值稱為公共價值。數據如果具有非排他性或非競爭性,就會產生外部性,并造成私人價值與公共價值之間的差異。這種外部性可正可負,沒有定論。
美國國稅局提出大麻行業的加密收益應納稅的改革建議:9月28日消息,美國國稅局局長De Lon Harris表示,由于美國國稅局將加密貨幣視為財產,因此大麻行業的加密收益應納稅。美國國稅局(U.S.Internal Revenue Service)繼續提出新的稅收改革建議,以監管美國的加密投資,最新的通知規定了大麻行業的稅收義務。該通知由美國國稅局局長De Lon Harris簽署,反映了美國聯邦機構的優先事項,以確保種植、分銷和銷售大麻的當地企業遵守加密貨幣稅。
此外,美國國稅局局長建議大麻企業與信譽良好的交易所合作,將加密貨幣轉換為美元。美國國稅局尚未要求企業明確報告高價值的加密交易。(Cointelegraph)[2021/9/28 17:12:37]
第二,數據與數據結合的價值,可以不同于它們各自價值之和,是另一種外部性。但數據聚合是否增加價值,也沒有定論。一方面,可能存在規模報酬遞增情形,比如更多數據更好地揭示了隱含的規律和趨勢。另一方面,可能存在規模報酬遞減情形,比如更多數據引入更多噪聲。但總的來說,數據容量越大,數據價值不一定越高,數據內容也很重要。比如,1小時的視頻監控數據,有價值數據可能僅有1-2秒。
數據價值的計量
1.絕對估值
鑒于數據價值的三個關鍵特征,數據的絕對估值比較難,沒有公認方法。目前行業實踐中有幾種主要方法,但都有缺陷。
第一,成本法,也就是將收集、存儲和分析數據的成本作為數據估值基準。這些成本有軟件和硬件方面的,也有知識產權和人力資源方面的,還有因安全事件、敏感信息丟失或名譽損失而造成的或有成本。數據收集和分析一般具有高固定成本、低邊際成本特征,從而有規模效應。成本法盡管便于實施,但很難考慮同樣數據對不同人、在不同時間點以及與其他數據組合時的價值差異。另外,德勤和阿里研究院指出,一些數據為企業生產經營的附加產物,獲取成本通常難以從業務中劃分出來而難以可靠計量。顯然,數據價值不一定高于成本,說明不是所有數據都值得收集、存儲和分析。
第二,收入法,也就是評估數據的社會和經濟影響,預測由此產生的未來現金流,再將未來現金流折現到當前。收入法在邏輯上類似公司估值中的折現現金流法,能考慮數據價值的三個關鍵特征,在理論上比較完善,但實施中則面臨很多障礙。一是對數據的社會和經濟影響建模難度很大。二是數據的期權價值如何評估。實物期權估值法是一個可選方法,但并不完美。
第三,市場法,也就是以數據的市場價格為基準,評估不在市場上的數據的價值。市場法類似股票市場的市盈率和市凈率估值方法。市場法的不足在于,很多數據是非排他性的或非競爭性的,很難參與市場交易。目前,數據要素市場有一些嘗試,但市場厚度和流動性都不夠,價格發現功能不健全。另外,一些公司兼并收購價格著包含著對數據的估值,但不易分離出來。
第四,問卷測試法。這個方法主要針對個人數據,通過問卷測試個人愿意收多少錢以出讓自己的數據,或愿意花多少錢保護自己的數據,從而評估個人數據的價值。這個方法應用面非常窄,實施成本較高。
2.相對估值
數據相對估值目標是,給定一組數據以及一個共同的任務,評估每組數據對完成該任務的貢獻。與絕對估值相比,相對估值要簡單一些,特別針對定量的數據分析任務。
在數據相對估值中,常見數據分組方法包括:一是變量/字段一樣,但屬于不同的觀察樣本;二是同樣的觀察樣本,但變量/字段不同。對常見預測性任務和描述性任務,統計學和數據科學建立了量化評估指標。比如,對預測任務,需做樣本外檢驗,評估預測誤差。在預測變量是離散型時,常用準確率、錯誤率以及操作特征曲線下方面積等指標。在預測變量是連續型時,常用標準誤差。對描述任務,需用樣本數據評估模型擬合效果,線性模型一般用R平方,非線性模型一般用似然函數。

使用Shapley值進行數據相對估值遵循以下步驟。第一步:定義數據集合及其元素。第二步:定義擬完成的任務。第三步:選擇完成任務所使用的模型及評估指標。第四步:對數據集合中元素形成的每一個數據子集(
動態 | 瑞士加密行業穩步增長:據bitcoin報道,總部位于祖格的投資者CV Venture Capital發布的一份新報告顯示,在瑞士版的硅谷,排名前50位的加密貨幣和區塊鏈相關公司的總價值如今達到440億美元,加密貨幣公司在這個小國總共雇傭了大約3000人。前50名中包括5家“獨角獸”,即市值超過10億美元的初創企業,突顯出瑞士加密行業的穩步增長。[2018/10/11]

〡N〡個元素,意味著2〡N〡個可能的數據子集),運行模型并獲得評估結果。第五步:根據Shapley值計算每個元素對完成任務的貢獻。此方法的主要不足是,隨著數據集合的元素數量上升,計算量將指數上升。主要優點是符合直覺,容易計算,而且源自經濟學的長期研究。Jiaetal.(2019)討論了如何優化使用Shapley值進行數據相對估值的計算過程。
數據相對估值說明,同一數據在用于不同任務,使用不同分析方法,或與不同數據組合時,體現出的價值是不同的。特別是,偏離數據集合“主流”的數據,在相對估值上可能比靠近數據集合“主流”的數據高,這顯示了“異常值”的價值。
三、數據要素的配置機制
在現實中,數據有多種類型和不同特征,相應產生了不同的配置機制。因為很多數據不適合參與市場交易,很多配置機制不屬于市場交易模式。換言之,市場化配置不等于市場交易模式。
這些機制都致力于解決數據要素配置中的兩個突出問題。第一,信息不對稱。數據要素配置機制涉及多個利益不一致的參與方。比如,數據主體往往不清楚自己數據在何時、因何目標或有何后果而被收集。數據生產者不清楚數據主體是否選擇性披露數據,以及在知道自己的數據被收集時是否會有針對性地調整行為,也不清楚生產出的數據對不同數據使用者的價值。數據使用者在事前很難完全了解數據對自己的價值。比如,數據相對估值就是在事后進行的。
第二,非完全契約。數據要素配置機制都可以表示成一系列契約的組合。但數據應用有豐富場景,數據價值鏈有多個環節,數據價值缺乏客觀計量標準,這些因素使得數據要素配置機制很難在事前覆蓋事后所有可能出現的情況。這既會影響數據主體分享數據以及數據生產者生產數據的激勵,也會影響數據價值在數據價值鏈中不同貢獻者之間的合理分配。
接下來,按照數據的經濟學特征以及應用場景,討論有代表性的數據要素配置機制。
作為公共產品的數據
數據作為公共產品時,由私人部門提供會有投資不足和供給不足的問題,一般由政府部門利用稅收收入提供。政府部門的數據開放和共享項目可以在這個框架下理解。政府部門應該在不涉密的前提下,盡可能向社會和市場開放政府數據,這樣才能最大化政府數據的公共價值。
2009年,美國聯邦政府推出數據開放門戶網站Data.gov,為之前分散在聯邦政府不同機構的網站上數據統一提供托管平臺。2019年,美國《開放政府數據法案》要求,除涉及國家安全和其他特殊原因的數據以外,聯邦政府應該在線發布它們擁有的數據,并且這些公開數據采取標準化、機器可讀的形式。
2016年以來,我國頒布《政務信息資源共享管理暫行辦法》、《公共信息資源開放試點工作方案》等一系列文件,開啟政務數據共享開放進程。《關于構建更加完善的要素市場化配置體制機制的意見》提出的第一個工作方向就是推進政府數據開放共享。
作為準公共產品的數據
作為準公共產品的數據如果在所有權上較為清晰,并且具有排他性,有以下三種主要的配置機制。
第一,作為俱樂部產品的數據,可以采取付費訂購模式,比如收費媒體信息終端。
第二,開放銀行模式。銀行通過應用程序界面將用戶數據開放給經授權的第三方機構,以促進用戶數據的開發使用。銀行既限定哪些用戶數據可開放,也限定向哪些機構開放。這實際上是部分實現用戶數據的可攜帶性。
第三,數據信托模式。根據BIPP的介紹,數據信托可以采取不同形式,比如法律信托、契約、公司以及公共和社區信托等。數據信托的主要目標包括:一是使數據可被共享;二是促進公共利益以及數據分享者的私人利益;三是尊重那些對數據有法律權利的人的利益;四是確保數據以合乎倫理和數據信托規則的方式共享。
金色財經獨家分析 區塊鏈技術不適用于所有行業:今日,人民日報海外版刊文稱:不是所有領域都能實現“區塊鏈+”,在當前區塊鏈發展階段,并非所有的領域都可以實現“區塊鏈+”,要防止新瓶裝舊酒,尤其要防止觸及監管紅線的行為。金色財經分析,目前區塊鏈發展還處在早期階段,技術上有許多需要晚上和發展的地方,盡管區塊鏈在金融產品很具有應用場景,另外包括區塊鏈落地的垂直賦能領域,內容、營銷、供應鏈、物聯網、金融等這些方向有著較強的應用場景。但是目前市場上的各個領域都在結合區塊鏈技術,區塊鏈技術也并不一定適合所有行業,很多所謂的區塊鏈項目都有“蹭熱度”的嫌疑。[2018/5/23]
互聯網平臺的PIK模式
前面已提到,在互聯網經濟中,如果個人數據不是由用戶對外提供,而是來自互聯網平臺對用戶特征和行為的觀察和記錄,那么所有權就很難界定清楚。現實中,互聯網平臺經常為用戶提供免費資訊和社交服務,目標是擴大用戶量,并獲得用戶的注意力和個人數據。在這個模式中,可以認為是用戶用自己的注意力和個人數據換取資訊和社交服務,因此被稱為PIK模式。互聯網平臺一方面是通過廣告收入變現用戶流量,另一方面基于用戶個人數據進行精準營銷和開發信貸產品等。
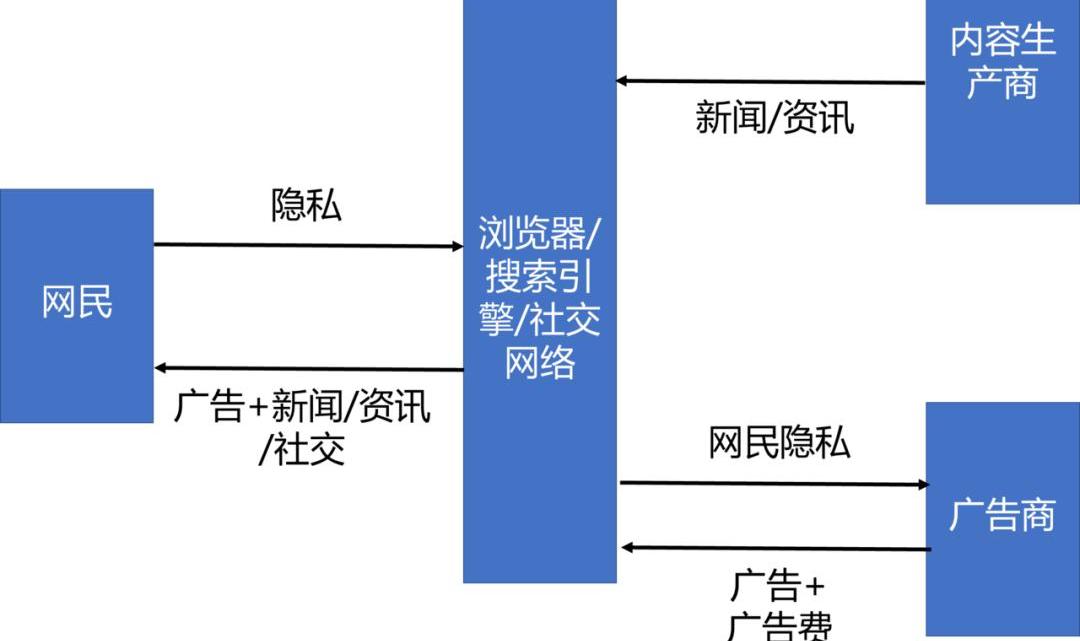
圖2:互聯網平臺的PIK模式
PIK模式主要有三個弊端:第一,互聯網平臺與用戶之間地位不平等,容易在未經用戶授權的情況下收集用戶數據,或過度收集用戶數據,或把從甲業務中收集到的個人數據用于乙業務,從而造成隱私侵犯和數據濫用問題。第二,互聯網平臺如果形成捕獲性生態,會鎖定用戶,并在事實上控制用戶數據。用戶很難將自己數據開放給或遷移到互聯網平臺的競爭對手。互聯網平臺通過數據壟斷在PIK模式下,數據控制者相對數據主體處于主導地位,并且數據控制者往往也是數據使用者,而數據主體對自己數據缺乏控制,在數據產權上有很多模糊不清之處。如何糾正PIK模式的弊端,是個人數據管理中的一個核心問題。
數據要素市場
很多數據因為有非排他性或非競爭性,參與市場交易都面臨限制。另一方面,非排他性或非競爭性造成的外部性,使得數據的私人價值與公共價值之間有差異,市場交易不一定能實現數據的最大社會價值。
在現實中,因為數據類型和特征的多樣性,以及數據價值缺乏客觀計量標準,目前并不存在一個集中化、流動性好的數據要素市場。但數據的點對點交易一直在發生,比如另類數據市場。這個市場中存在大量的另類數據提供商。它們對數據的處理程度從淺到深大致可分為原始數據提供者、輕處理數據提供者和信號提供者。這個市場已發展出咨詢中介、數據聚合商和技術支持中介等,作為連接數據買方和數據提供方之間的橋梁。其中,咨詢中介為買方提供關于另類數據購買、處理及相關法律事宜的咨詢,以及數據供應商信息。數據聚合商提供集成服務,買方只需和它們協商即可,無需進入市場與分散的數據提供商打交道。技術支持中介為買方提供技術咨詢,包括數據庫和建模等。
可見,另類數據市場發展已很完善,形成了豐富的分工合作關系,但這個市場仍很不透明且非標準化。這是目前數據交易面臨的普遍問題。更不容忽視的是非法數據交易,比如交易個人隱私數據的“數據黑市”和“數據黑產”。2019年以來,我國對“數據黑產”開展了集中整頓。
如何建立合規有效的數據要素市場?一個可行選項是使用密碼學技術,包括可驗證計算、同態加密和安全多方計算等。
對復雜的計算任務,可驗證計算會生成一個簡短證明。只要驗證這個簡短證明,就能判斷計算任務是否被準確執行,不需要重復執行計算任務。在同態加密和安全多方計算下,對外提供數據時,采取密文而非明文形式,從而使數據具備排他性。這些密碼學技術支持數據確權,使得在不影響數據所有權的前提下交易數據使用權成為可能,從而構建數據交易的產權基礎,并影響數據主體和數據控制者的經濟利益關系。區塊鏈技術用于數據存證和使用授權,也在數據產權界定中發揮重大作用。后文將討論,除了技術以外,數據產權界定也可以通過制度設計來實施。
但即便如此,基于密碼學的數據要素市場也不同于傳統市場。首先,同一數據在加密后可以同時向多方提供,因此仍然是非競爭性的,除非數據使用者與數據控制者之間簽署保密協議,要求后者不得再將數據提供給其他人使用,或者數據有很強時效性,一經使用后很快失去價值。換言之,數據很難成為私人產品,從而很難像私人產品那樣參與市場交易。其次,同一數據對不同人的價值可以差別很大。這使得在基于密碼學的數據使用權交易中,應用場景對數據價值的影響,可能超過了數據本身特征和內容的影響,從而很難從數據交易價格中提煉出有價值的定價信息。因此,基于密碼學的數據要素市場不會采取“對同一商品,多個買方競價,價高者得”的要素配置模式。
需要說明的是,數據要素市場不一定是簡單的撮合買賣模式,可以存在其他復雜的模式。比如,Markit公司建立CDS定價數據服務的模式值得研究。國際金融危機之前,CDS是純粹的場外交易,信息披露很不完善。CDS頭寸是金融機構重要的商業機密,很難與其他金融機構分享。參與CDS市場的金融機構只知道自己的CDS頭寸,但不知道市場的整體情況。CDS市場沒有好的指數,信息不對稱程度很高。Markit公司成立于2003年,其股東包含主要的CDS做市商。這些金融機構股東把自己的CDS數據上傳到Markit,Markit整合得到CDS市場數據后以收費方式對外提供,包括定價和參考數據、指數產品、估值和交易服務等。Markit的股東金融機構在不泄露自己商業機密的情況下,不僅從Markit的工作中獲知CDS市場整體情況,還從Markit的業務增長中獲得投資收益。Markit盡管沒有對數據進行顯式定價,但通過股權的利益綁定功能以及數據整合的“1+1>2”效應,解決了數據共享中的激勵相容問題。這是一個復雜而巧妙的數據交易模式。我國個人征信市場的百行征信公司也可以在類似框架下理解。
數據產權界定
從前面介紹的數據要素配置機制可以看出,數據產權界定是數據要素有效配置的基礎。數據產權主要分為所有權和控制權。數據控制權包括誰能使用數據,如何使用數據,以及能否進一步對外分享數據等。在公司治理中,所有權和控制權是統一的——股東擁有公司,股東大會是公司的最高權力機關。但數據的所有權和控制權可以分離,特別是對所有權不清晰的個人數據。數據產權可以通過技術來界定,比如可驗證計算、同態加密和安全多方計算等密碼學技術。數據產權還可以通過制度設計來界定。
2018年5月,歐盟開始實施《通用數據保護條例》。GDPR給予數據主體廣泛權力:第一,被遺忘權,指數據主體有權要求數據控制者刪除其個人數據,以避免個人數據被傳播。第二,可攜帶權,指數據主體有權向數據控制者索取本人數據并自主決定用途。第三,數據主體在自愿、基于特定目的且在與數據控制者地位平衡等情況下,授權數據控制者處理個人數據,但授權在法律上不具備永久效力,可隨時撤回。第四,特殊類別的個人數據的處理條件,比如醫療數據。
GDPR還提高了對數據控制者的要求:第一,企業作為數據控制者必須在事前數據采集和事后數據泄露兩個環節履行明確的告知義務。第二,數據采集與數據使用目標的一一對應原則,以及數據采集最小化原則。第三,個人數據跨境傳輸條件。總的來說,GDPR引入了數據產權的精細維度,包括被遺忘權、可攜帶權、有條件授權和最小化采集原則等,建立了數據管理的制度范式。這些做法被歐盟以外的很多國家和地區所采納。2019年5月,我國網信辦發布《數據安全管理辦法》。2019年12月,國家網信辦、工信部、部和市場監管總局四部門聯合印發《App違法違規收集使用個人信息行為認定方法》。
個人數據管理的核心問題隱私保護。隱私涉及個人與他人、私有與公開的邊界,是個人尊嚴、自主和自由的重要方面。隱私不排斥共享個人信息,而是要有效控制共享過程,在保護和共享個人數據之間做好平衡。對個人數據,控制權和隱私保護的重要性超過所有權。這一點在GDPR中有體現。
四、小結
本文對數據要素的特征、價值和配置機制進行了初步研究,主要結論如下。
數據作為信息科學中一個基本但復雜的概念,對其的理解離不開對信息和知識等相關概念的辨析,而DIKW模型為此提供了一個合適的分析框架。根據DIKW模型,智慧、知識、信息和數據之間依次存在從窄口徑到寬口徑的從屬關系。數據是觀察的產物。數據經過認知過程處理后得到信息,給出關于誰、什么、何處和何時等問題的答案。知識是對數據和信息的應用,給出關于如何做的答案。智慧則有鮮明的價值判斷意味,在很多場合與對未來的預測和價值取向有關。
數據有多個維度的技術特征,但數據的經濟學特征更復雜。數據可以產生價值,因此具有資產屬性。數據兼有商品和服務的特征。很多數據屬于公共產品,可以由任何人為任何目的而自由使用、改造和分享。因為大部分數據是非競爭性的,屬于私人產品和公共資源的數據較少。數據的所有權不管在法律上還是在實踐中都是一個復雜問題,特別對個人數據。因此,把數據比喻成石油,不如把數據比喻成陽光更為合適。
數據經過處理并與其他數據整合后,再經分析形成可行動的洞見,最終由行動產生價值。數據價值在微觀層面體現為對使用者效用的提高,在宏觀層面體現為從數據中提煉出的信息、知識和智慧對全要素生產率的提高。然而,數據價值缺乏客觀計量標準,主要有三方面原因:一是同樣數據對不同人的價值可以大相徑庭;二是數據價值隨時間變化;三是數據會產生外部性。
數據價值的計量包括絕對估值和相對估值。數據絕對估值比較難,沒有公認方法。目前行業主要使用成本法、收入法、市場法和問卷測試法,但都有缺陷。數據相對估值是給定一組數據以及一個共同的任務,評估每組數據對完成該任務的貢獻。與絕對估值相比,相對估值要簡單一些。針對定量的數據分析任務,可以使用Shapley值進行相對估值。
數據有多種類型和不同特征,產生了不同的配置機制。這些配置機制都致力于數據要素配置中的信息不對稱和非完全契約問題。本文主要討論了四種配置機制。
第一,作為公共產品的數據,一般由政府部門利用稅收收入提供。政府部門應該在不涉密的前提下,盡可能向社會和市場開放政府數據,這樣才能最大化政府數據的公共價值。
第二,作為準公共產品的數據如果在所有權上較為清晰,并且具有排他性,可以采取俱樂部產品式的付費模式、開放銀行模式以及數據信托模式。
第三,在互聯網經濟中,很多個人數據的所有權很難界定清楚,現實中常見PIK模式,本質上是用戶用自己的注意力和個人數據換取資訊和社交服務,但PIK模式存在很多弊端。
第四,很多數據因為有非排他性或非競爭性,不適合參與市場交易。換言之,市場化配置不等于市場交易模式。現實中并不存在一個集中化、流動性好的數據要素市場。數據的點對點交易盡管一直在發生,但很不透明且非標準化,并且非法數據交易是一個不容忽視的問題。
數據產權界定是數據要素有效配置的基礎。可驗證計算、同態加密和安全多方計算等密碼學技術支持數據確權,使得在不影響數據所有權的前提下交易數據使用權成為可能,從而構建數據交易的產權基礎。區塊鏈技術用于數據存證和使用授權,也在數據產權界定中發揮重大作用。但即便如此,基于密碼學的數據要素市場也不同于傳統市場,不會采取“對同一商品,多個買方競價,價高者得”的要素配置模式。
除了技術以外,數據產權還可以通過制度設計來界定。GDPR引入了數據產權的精細維度,包括被遺忘權、可攜帶權、有條件授權和最小化采集原則等,建立了數據管理的制度范式。這些做法被歐盟以外的很多國家和地區所采納。個人數據管理的核心問題隱私保護。對個人數據,控制權和隱私保護的重要性超過所有權。
參考文獻
1、Ackoff,R.L.,1989,“FromDatatoWisdom”,JournalofAppliedSystemAnalysis,16:3-9.
2、Acquisti,A.,C.Taylor,andL.Wagman,2016,"TheEconomicsofPrivacy",JournalofEconomicLiterature,54(2):442-292
3、BennettInstituteforPublicPolicy(BIPP),2020,TheValueofData,
https://www.bennettinstitute.cam.ac.uk/research/research-projects/valuing-data/
4、JiaR.,D.Dao,B.Wang,F.Hubis,N.Hynes,N.Gurel,B.Li,C.Zhang,D.Song,andC.Spanos,2019,"TowardsEfficientDataValuationBasedontheShapleyValue".
5、PlatON,2018,"PlatON:AHigh-EfficiencyTrustlessComputingNetwork",https://www.platon.network/static/pdf/en/PlatON_A%20High-Efficiency%20Trustless%20Computing%20Network_Whitepaper_EN.pdf
6、Rowley,J.,2007,“TheWisdomHierarchy:RepresentationoftheDIKWHierarchy”,JournalofInformationandCommunicationScience,33(2):163-180.
7、德勤和阿里研究院,2019,《數據資產化之路——數據資產的估值與行業實踐》
8、李小加,2020,《呼吁成立“數據要素產業化聯盟”》,香港交易所
9、于施洋、王建冬和郭巧敏,2020,《中國構建數據新型要素市場體系面臨的挑戰與對策》,《電子政務》2020年第3期
注:2018年1月,《紐約時報》StevenJohnson在比特幣價格處于歷史最高點的時候寫下了這篇文章.
1900/1/1 0:00:00由于機構投資者建立了短期看漲頭寸,本月芝商所的比特幣期權數量增長了1000%,但是BTC的現貨價格會上漲嗎? 比特幣期權市場終于在CME起飛.
1900/1/1 0:00:00據Decrypt5月6日報道,比特幣開發者們在減半前的幾周已經忙得不可開交,僅在4月份,BitcoinCore就有510次代碼提交,這比比特幣誕生以來的任何月份都要多.
1900/1/1 0:00:00今年以來,二三線城市推進區塊鏈產業發展的步伐開始加快。互鏈脈搏梳理統計發現,從今年3月份至今,已經有超過10多個二三線省市密集出臺了區塊鏈產業發展的相關政策,并計劃再建9個區塊鏈產業園區.
1900/1/1 0:00:00中國四大礦機企業之一的芯動與中國芯片封測龍頭企業長電科技的糾紛還在持續。5月1日、2日,雙方互發聲明進行解釋.
1900/1/1 0:00:004月23日,比特幣耶穌RogerVer在推特上轉發了一篇自己的帖子,他表示,“如果比特幣仍然可以像錢一樣運作,我很樂意繼續推廣它。今天,讓我推廣像BTC這樣用戶體驗糟糕的產品,我會感到很尷尬.
1900/1/1 0:00:00


