






 BTC/HKD-0.49%
BTC/HKD-0.49% ETH/HKD-0.42%
ETH/HKD-0.42% LTC/HKD-0.33%
LTC/HKD-0.33% DOT/HKD+0.93%
DOT/HKD+0.93% ADA/HKD+0.32%
ADA/HKD+0.32% SOL/HKD+0.2%
SOL/HKD+0.2% XRP/HKD+0.63%
XRP/HKD+0.63% DOGE/US-0.58%
DOGE/US-0.58%導讀
首先問大家一個小問題?區塊鏈的賬本數據存儲格式主要是什么類型的?
相信聰明的你一定知道是Key-Value類型存儲。
下一個問題,這些Key-Value數據在底層數據庫如何高效組織?
答案就是我們本期介紹的內容:LSM。
LSM是一種被廣泛采用的持久化Key-Value存儲方案,如LevelDB,RocksDB,Cassandra等數據庫均采用LSM作為其底層存儲引擎。
據公開數據調研,LSM是當前市面上寫密集應用的最佳解決方案,也是區塊鏈領域被應用最多的一種存儲模式,今天我們將對LSM基本概念和性能進行介紹和分析。
LSM-Tree背景:追本溯源
LSM-Tree的設計思想來自于一個計算機領域一個老生常談的話題——對存儲介質的順序操作效率遠高于隨機操作。
如圖1所示,對磁盤的順序操作甚至可以快過對內存的隨機操作,而對同一類磁盤,其順序操作的速度比隨機操作高出三個數量級以上,因此我們可以得出一個非常直觀的結論:應當充分利用順序讀寫而盡可能避免隨機讀寫。
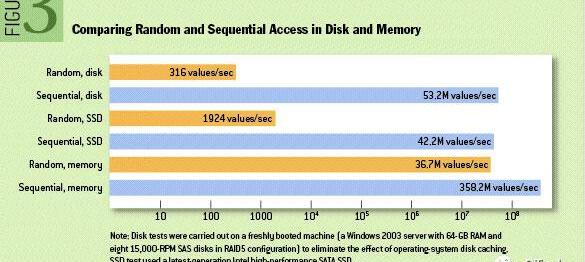
Figure1Randomaccessvs.Sequentialaccess
現場 | 劉航:區塊鏈是可信的數據技術 必將與大數據融合發展:金色財經現場報道,由中關村科技園區管理委員會、中國信息協會指導,中國信息化發展研究院、中國通信工業協會區塊鏈專委會主辦的“區塊鏈&數字經濟高峰論壇暨2019第八屆中關村大數據日”于12月12日在北京中關村舉行。中關村科技園區管理委員會副巡視員劉航發表致辭,他表示本次大會是加強合作,共謀發展的好時機。當今隨著人工智能、大數據、物聯網、5G,特別是區塊鏈應用的創新,區塊鏈技術快速邁向萬物互聯,萬物上鏈的規模化階段,催生了一批新產業新業態新模式。區塊鏈實際上是可信的數據技術,必將與大數據融合發展。中關村率先布局大數據展業,2016年成立中關村區塊產業聯盟,成立了25家大數據領域的協同創新平臺,支持基金超過累計2億元,大數據企業達到1600余家,產業規模增長達到20%以上,領先全國。[2019/12/12]
考慮到這一點,如果我們想盡可能提高寫操作的吞吐量,那么最好的方法一定是不斷地將數據追加到文件末尾,該方法可將寫入吞吐量提高至磁盤的理論水平,然而也有顯而易見的弊端,即讀效率極低,我們稱這種數據更新是非原地的,與之相對的是原地更新。
為了提高讀取效率,一種常用的方法是增加索引信息,如B+樹,ISAM等,對這類數據結構進行數據的更新是原地進行的,這將不可避免地引入隨機IO。
LSM-Tree與傳統多叉樹的數據組織形式完全不同,可以認為LSM-Tree是完全以磁盤為中心的一種數據結構,其只需要少量的內存來提升效率,而可以盡可能地通過上文提到的Journaling方式來提高寫入吞吐量。當然,其讀取效率會稍遜于B+樹。
聲音 | 光明日報:充分運用區塊鏈等新技術 創新黨建工作載體和方式方法:《光明日報》今天發表題為“將黨的優勢轉化為城市精細化治理優勢”的評論文章。文中提到,要運用網絡信息技術手段,提升智慧黨建引領社會治理水平。充分運用大數據、區塊鏈、人工智能等新技術,創新黨建工作載體和方式方法,構建全天候、全覆蓋、立體化的智慧黨建工作體系。統籌推進智慧黨建和智慧城市建設,設立大數據中心歸集分散于各部門的基礎信息和數字資源,共建共享技術支撐平臺、大數據應用平臺。[2019/10/23]
LSM-Tree數據結構:抽絲剝繭
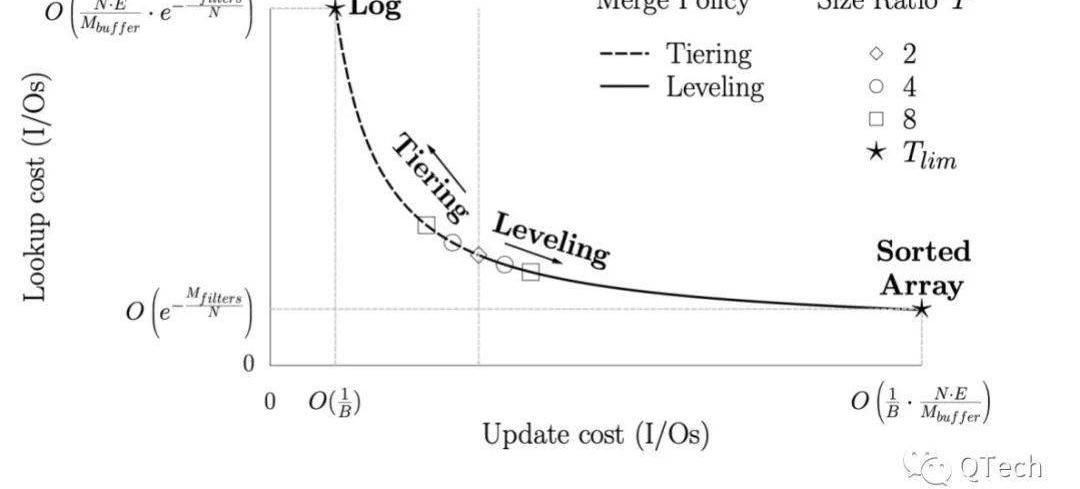
圖2展示了LSM-Tree的理論模型(a)和一種實現方式(b)。LSM-Tree是一種層級的數據結構,包含一層空間占用較小的內存結構以及多層磁盤結構,每一層磁盤結構的空間上限呈指數增長,如在LevelDB中該系數默認為10。
Figure2LSM與其LevelDB實現
對于LSM-Tree的數據插入或更新,首先會被緩存在內存中,這部分數據往往由一顆排序樹進行組織。
當緩存達到預設上限,則會將內存中的數據以有序的方式寫入磁盤,我們稱這樣的有序列為一個SortedRun,簡稱為Run。
隨著寫入操作的不斷進行,L0層會堆積越來越多的Run,且顯然不同的Run之前可能存在重疊部分,此時進行某一條數據的查詢將無法準確判斷該數據存在于哪個Run中,因此最壞情況下需要進行等同于L0層Run數量的I/O。
聲音 | 羅斯·萊克:中國可以更好地結合區塊鏈等技術 推出新產品新服務:據中國金融新聞網報道,國際貨幣基金組織副法務總監、FINTECH工作組聯合負責人羅斯·萊克稱,從IMF的角度來看,金融科技的含義十分廣泛,不只限于各項技術,而是覆蓋了互聯網、云計算、分布式賬簿計劃、區塊鏈及加密貨幣等系統,也包括人工智能、大數據、生物統計數據、API及移動通信等科技。“這些技術在中國都得到了很好的體現。中國可以將以上技術更好地結合,推出激動人心的新產品與新服務。”[2018/9/4]
為了解決該問題,當某一層的Run數目或大小到達某一閾值后,LSM-Tree會進行后臺的歸并排序,并將排序結果輸出至下一層,我們將一次歸并排序稱為Compaction。如同B+樹的分裂一樣,Compaction是LSM-Tree維持相對穩定讀寫效率的核心機制,我們將會在下文詳細介紹兩種不同的Compaction策略。
另外值得一提的是,無論是從內存到磁盤的寫入,還是磁盤中不斷進行的Compaction,都是對磁盤的順序I/O,這就是LSM擁有更高寫入吞吐量的原因。
Levelingvs.Tiering:一讀一寫,不分伯仲
LSM-Tree的Compaction策略可以分為Leveling和Tiering兩種,前者被LevelDB,RocksDB等采用,后者被Cassandra等采用,稱采用Leveling策略的的LSM-Tree為LeveledLSM-Tree,采用Tiering的LSM-Tree為TieredLSM-Tree,如圖3所示。
聲音 | 納斯達克報告:只有5%受訪公司應用了區塊鏈技術 :根據納斯達克新近的報告,股票市場和交易所的IT供應商現在還處于探索分布式賬本好處的初期階段,只有5%的受訪公司表示以某種形式應用了區塊鏈技術。70%的IT供應商表示他們在開發測試項目,20%表示沒有相關計劃,5%表示缺乏相關技術和人才。[2018/6/27]
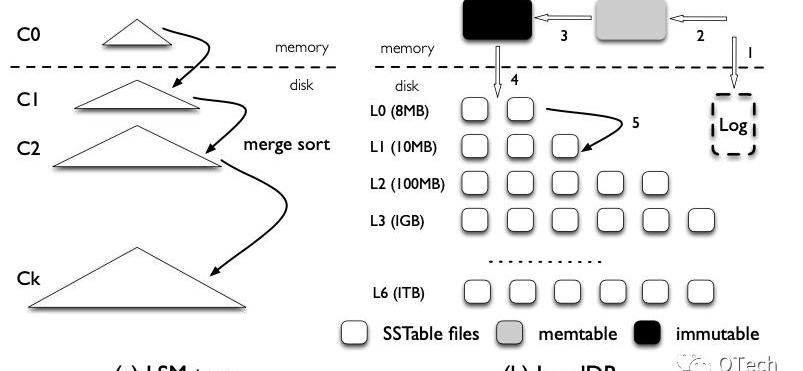
Figure3兩種Compaction策略對比
▲Leveling
簡而言之,Tiering是寫友好型的策略,而Leveling是讀友好型的策略。在Leveling中,除了L0的每一層最多只能有一個Run,如圖3右側所示,當在L0插入13時,觸發了L0層的Compaction,此時會對Run-L0與下層Run-L1進行一次歸并排序,歸并結果寫入L1,此時又觸發了L1的Compaction,此時會對Run-L1與下層Run-L2進行歸并排序,歸并結果寫入L2。
▲Tiering
反觀Tiering在進行Compaction時并不會主動與下層的Run進行歸并,而只會對發生Compaction的那一層的若干個Run進行歸并排序,這也是Tiering的一層會存在多個Run的原因。
▲對比分析
區塊鏈領域首個國家標準獲批立項:《信息技術 區塊鏈和分布式賬本技術 參考架構》:據中國區塊鏈技術和產業發展論壇官方公眾號消息,根據《國家標準委關于下達2017年第四批國家標準制修訂計劃的通知》(國標委綜合[2017]128號),《信息技術 區塊鏈和分布式賬本技術 參考架構》作為區塊鏈領域的首個國家標準獲批立項。中國區塊鏈技術和產業發展論壇于2016年10月18日,在工業和信息化部、國家標準化管理委員會工業標準二部的指導下,由中國電子技術標準化研究院、螞蟻金服、萬向控股、微眾銀行、平安保險、樂視金融、萬達網絡科技等共同發起成立。[2018/1/5]
相比而言,Leveling方式進行得更加貪婪,進行了更多的磁盤I/O,維持了更高的讀效率,而Tiering則相正好反。
本節我們將對LSM-Tree的設計空間進行更加形式化的分析。
LSM層數

布隆過濾器
LSM-Tree應用布隆過濾器來加速查找,LSM-Tree為每個Run設置一個布隆過濾器,在通過I/O查詢某個Run之前,首先通過布隆過濾器判斷待查詢的數據是否存在于該Run,若布隆過濾器返回Negative,則可斷言不存在,直接跳到下個Run進行查詢,從而節省了一次I/O;而若布隆過濾器返回Positive,則仍不能確定數據是否存在,需要消耗一次I/O去查詢該Run,若成功查詢到數據,則終止查找,否則繼續查找下一個Run,我們稱后者為假陽現象,布隆過濾器的過高的假陽率會嚴重影響讀性能,使得花費在布隆過濾器上的內存形同虛設。限于篇幅本文不對布隆過濾器做更多的介紹,直接給出FPR的計算公式,為公式2.
其中是為布隆過濾器設置的內存大小,為每個Run中的數據總數。讀寫I/O
考慮讀寫操作的最壞場景,對于讀操作,認為其最壞場景是空讀,即遍歷每一層的每個Run,最后發現所讀數據并不存在;對于寫操作,認為其最壞場景是一條數據的寫入會導致每一層發生一次Compaction。
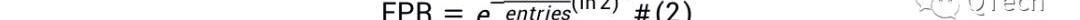
核心理念:基于場景化的設計空間
基于以上分析,我們可以得出如圖4所示的LSM-Tree可基于場景化的設計空間。
簡而言之,LSM-Tree的設計空間是:在極端優化寫的日志方式與極端優化讀的有序列表方式之間的折中,折中策略取決于場景,折中方式可以對以下參數進行調整:

當Level間放大比例時,兩種Compaction策略的讀寫開銷是一致的,而隨著T的不斷增加,Leveling和Tiering方式的讀開銷分別提高/減少。
當T達到上限時,前者只有一層,且一層中只有一個Run,因此其讀開銷到達最低,即最壞情況下只需要一次I/O,而每次寫入都會觸發整層的Compaction;
而對于后者當T到達上限時,也只有一層,但是一層中存在:

因此讀開銷達到最高,而寫操作不會觸發任何的Compaction,因此寫開銷達到最低。
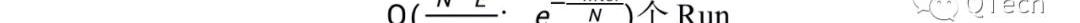
Figure4LSM由日志到有序列的設計空間
事實上,基于圖4及上文的分析可以進行對LSM-Tree的性能進一步的優化,如文獻對每一層的布隆過濾器大小進行動態調整,以充分優化內存分配并降低FPR來提高讀取效率;文獻提出“LazyLeveling”方式來自適應的選擇Compaction策略等。
限于篇幅本文不再對這些優化思路進行介紹,感興趣的讀者可以自行查閱文獻。
小結
LSM-Tree提供了相當高的寫性能、空間利用率以及非常靈活的配置項可供調優,其仍然是適合區塊鏈應用的最佳存儲引擎之一。
本文對LSM-Tree從設計思想、數據結構、兩種Compaction策略幾個角度進行了由淺入深地介紹,限于篇幅,基于本文之上的對LSM-Tree的調優方法將會在后續文章中介紹。
作者簡介葉晨宇來自趣鏈科技基礎平臺部,區塊鏈賬本存儲研究小組
參考文獻
.O’NeilP,ChengE,GawlickD,etal.Thelog-structuredmerge-tree(LSM-tree).ActaInformatica,1996,33(4):351-385.
.JacobsA.Thepathologiesofbigdata.CommunicationsoftheACM,2009,52(8):36-44.
.LuL,PillaiTS,GopalakrishnanH,etal.Wisckey:Separatingkeysfromvaluesinssd-consciousstorage.ACMTransactionsonStorage(TOS),2017,13(1):1-28.
.DayanN,AthanassoulisM,IdreosS.Monkey:Optimalnavigablekey-valuestore//Proceedingsofthe2017ACMInternationalConferenceonManagementofData.2017:79-94.
.DayanN,IdreosS.Dostoevsky:Betterspace-timetrade-offsforLSM-treebasedkey-valuestoresviaadaptiveremovalofsuperfluousmerging//Proceedingsofthe2018InternationalConferenceonManagementofData.2018:505-520.
.LuoC,CareyMJ.LSM-basedstoragetechniques:asurvey.TheVLDBJournal,2020,29(1):393-418.
近日,Messari創始人RyanSelkis發布了長達134頁的《2021年加密投資理論報告》.
1900/1/1 0:00:00本文作者:HashkeyCapital數字資產合規入場渠道概述與更新我們去年中期進行了數字資產合規入場渠道商業圖景的梳理,這一年我們看到一些新的趨勢和競爭格局的變化,于是做了進一步的更新.
1900/1/1 0:00:00OKExBTC/USDT永續合約: 如圖所示,昨天的調整在我們多次強調的25800一線短期強弱分界線上方止跌,并且隨后逐步上破了昨天晚評中提醒留意的小周期下降三角形,短期風險被化解.
1900/1/1 0:00:00撰文:7 一份包含超過27萬條賬戶信息的數據庫文件成為了成為了比特幣硬件錢包制造商Ledger揮之不去的夢魘,這份文件在RaidForums上被已極低的售價賣出.
1900/1/1 0:00:00文︱胖墩兒 比特幣繼12月16日突破2萬美元整數關口后,20日上攻至24188美元/枚,再次刷新歷史高點。暴漲之下,引起眾多主流媒體關注.
1900/1/1 0:00:00據TheBlockCrypto12月23日報道,瑞士加密貨幣銀行SEBA已完成了B輪融資。SEBA的首席營銷官SandraFrankDudler告訴TheBlock,這輪融資金額為2000萬瑞士.
1900/1/1 0:00:00


