






 BTC/HKD-0.16%
BTC/HKD-0.16% ETH/HKD-0.11%
ETH/HKD-0.11% LTC/HKD+1.02%
LTC/HKD+1.02% DOT/HKD+1.2%
DOT/HKD+1.2% ADA/HKD-0.69%
ADA/HKD-0.69% SOL/HKD-0.28%
SOL/HKD-0.28% XRP/HKD-0.38%
XRP/HKD-0.38% DOGE/US+0.56%
DOGE/US+0.56%簡介
如果你想學鬼步舞 (shuffle dance) 的話,那你就走錯地方了。但相信我,Eth2里的混洗 (shuffle) 也一樣讓人興奮。
混洗列表是以太坊2.0里一個基本運算。它主要用于在每12秒的slot里偽隨機挑選驗證者來組成委員會,以及在每個slot里選出信標鏈區塊的提議者。
混洗似乎相當簡單。盡管它有一些隱患需要注意,這些隱患在計算機科學里是非常容易理解的。其中的黃金標準大概就是Fisher-Yeats shuffle了。那我們為什么不在Eth2里使用它呢?我將在文末詳細解釋,但簡單來說就是——輕客戶端。
我們用的混洗算法是swap-or-not,而不是Fisher-Yates。這個選擇是基于這篇本來用于構建加密方案的論文。我最近在Eth2客戶端Teku中重寫我們的實現,因此我想趁熱把它寫出來。
Swap-or-Not混洗算法
一輪的操作過程
混洗以輪次進行。每輪的過程是一樣的,因此我在下面只會演示一輪的過程,它比看上去簡單多了。
選擇一個軸心點并找出第一個鏡像索引
首先,我們選一個軸心索引p,這是基于輪次和其他一些種子數據,通過偽隨機選出的。這個軸心選出后就在該輪次里固定了。
STEPN在以太坊上的活躍用戶跌破兩千,距8月最高點下降約60%:金色財經報道,據Dune Analytics數據顯示,9月1日,STEPN在以太坊上活躍用戶達到1991,較8月最高點(4872)下降約60%。[2022/9/5 13:08:33]
基于這個軸心點,我們在p和0的中間點選出一個鏡像索引m1,即m1=p/2。(為了方便解釋,我們將忽略麻煩的差一錯誤舍入問題)

軸心點和第一個鏡像index
從第一個鏡像索引到軸心點,替換與否
?對于鏡像索引m1和軸心索引p之間的每個索引,我們隨機決定是否對這些元素進行替換。
比如對于索引i1,如果我們選擇不替換,那么我們就繼續選下一個索引。
如果我們決定替換,那么我們將i1上的列表元素與i1’上的替換,即它在鏡像索引上的圖像。也就是i1與i1’=m1-(i1-m1)替換,這樣i1和i1’到m1的距離是相等的。
我們對每個m1和p之間的索引都做相同的swap-or-not的決定。
USDC發行方Centre將7個以太坊地址列入黑名單:4月24日消息,據以太坊鏈上和DuneAnalytics統計的數據顯示,美元穩定幣USDC發行方Centre聯盟(由Coinbase和Circle共同發起成立)于4月21日將7個以太坊地址列入黑名單。這也是自2020年6月16日Centre第一次將地址列入黑名單以來的第二次列入黑名單操作。[2021/4/24 20:54:46]

從第一個鏡像索引到軸心的swap-or-not決定
計算第二個鏡像索引
在做完從m1到p的所有索引決定后,我們現在找到第二個以m2為中點的鏡像索引,即到p和列表末端的距離相等的點。也就是m2=m1+n/2。

第二個鏡像索引
從軸心點到第二個鏡像,替換與否
最后,我們重復swap-or-not的過程,考慮所有點到軸心p替換的決定,即p到第二個鏡像m2的決定。如果我們選擇不替換,就繼續下一個。如果我們選擇替換,那么我們在鏡像索引m2上把j1上的元素與它在j1’上的鏡像進行替換。
CME以太坊期貨交易量及未平倉合約創歷史新高:金色財經報道,CME以太坊期貨的交易量及未平倉合約在四月初創歷史新高。根據CME發布的最新數據,截至4月7日,未平倉合約為1,822份,約合91,100枚ETH(約2.25億美元)。交易量也創下了新的高點2,247份,代表112,500枚ETH(或2.78億美元)。[2021/4/15 20:24:28]
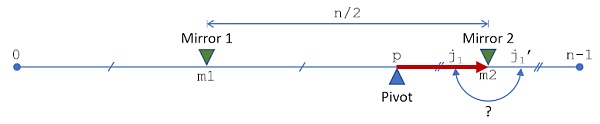
從軸心到第二個鏡像索引的swap-or-not決定
組合起來
在一輪的最后,我們都已經考慮了m1到m2之間所有的索引,即所有索引的一半,且無論替換與否,每個索引都在另一半有一個特定的索引。因此,關于替換與否,所有的索引都已被考慮過一次了。
下一輪以增加 (或減少) 輪次開啟,這樣我們會有一個新的軸心索引,然后開始循環上述的過程。
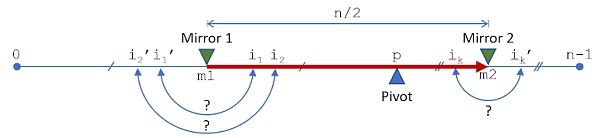
同一輪中從一個鏡像移向另一個鏡像的過程
Tether在以太坊網絡增發3億枚USDT:金色財經報道,Whale Alert數據顯示,北京時間01月09日02:59,Tether在以太坊網絡增發3億枚USDT。增發哈希為78802fd4db62434a7c966d304d8f80897cf40e8cd459635c8762a0ea39aa9da2。[2021/1/9 15:41:54]
有趣之處
巧妙的地方
當在決定要不要替換的時候,這個算法會巧妙地選擇候選索引或其鏡像中的更高者。意思是當在軸心之下時,被選擇的是i_1而不是i_1’;當在軸心之上時,被選擇的時i_k’而不是i_k。這意味著,我們可以靈活遍歷列表中的索引:我們可以將0到m1和p到m2分為兩個獨立的循環,或將兩者合在同一個從m1到m2的循環,如我在上文所描繪(和實現)的。這兩種做法的結果是一樣的:無論我考慮的是i_1還是鏡像i_1’都沒有關系;替換與否得出的是相同的結果。
輪次
在Eth2,上述的過程會進行90次。原始論文里提到要經歷6lgN個輪次才能“開始在選擇性密碼攻擊 (CCA) 上出現較好的安全性界限”,其中N是列表的長度。在Vitalik的注釋規范里,他說“密碼學專家建議我們4log2N個輪次就能提供足夠的安全性了”。
聲音 | 前以太坊核心開發者:波卡平行鏈插槽數量有限 需競拍才能獲得:據區塊律動消息,針對波卡平行鏈開始要如何分配,如何成為平行鏈等問題,前以太坊核心開發者Web3foundation對此表示,1. 平行鏈插槽是有一定數量的,開始是數量不多,后面慢慢增加。2. 會有未經許可的,插槽出租的市場行為。為了保證平行鏈插槽的公平性,會使用競拍的方式。任何人都可以參加。3. 如果有人(個人或智能合約)贏得拍賣,可以不需要任何許可,直接部署他們的平行鏈。4. 平行鏈插槽不是無限時間使用的。5. 由Web3基金會管理的平行鏈,會保留一段時間。此外,波卡平行鏈插槽將從大約5個增加到50到200個插槽,而由Web3 Foundation管理的平行鏈現在有4種。[2019/5/31]
在Eth2里驗證者數量的絕對最大值,也就是我們需要混洗的列表最大次數,大概是222 (420萬)。Vitalik給出的預估值是88輪,在論文里的預估值是92輪 (假設lg是自然對數)。因此,我們現在處于一個大致正確的范圍,特別是我們最后非常可能沒有這么多活躍驗證者。
基于列表長度來調整輪次可能會得出有趣的結果,但我們不會這么做,這可能是不必要的優化。
有意思的是,當Least Authority審計信標鏈的規范時,他們一開始發現在選擇區塊提議者的混洗中是有偏倚的 (參考Issue F)。但結果是他們錯誤使用了只有10輪次的混洗配置。當他們將混洗配置增加到90輪 (我們在主網使用的輪次) 時,偏倚的情況消失了。
(偽) 隨機
混洗算法要求我們在每一輪里隨機選一個軸心點,且在每輪里隨機選擇是否對每個元素進行替換。
在Eth2,我們肯定會從一個種子值產生隨機性,由此這同一個種子總會產生同一個混洗結果。
軸心指標是由把與輪次串聯的種子進行8字節的SHA2哈希產生的,軸心索引由種子值SHA2哈希的八個字節生成,該種子值與輪次相串聯,因此它通常在每輪里都有會改變。
用來決定是否要替換元素的決定性數位從以下幾個元素中提取:種子的SHA256哈希、輪次、列表上元素的索引。
效率
這個混洗算法比Fisher-Yates算法要慢得多。如果Fisher-Yates算法需要N次混洗的話,我們的算法平均需要90N/4次。我們還要考慮偽隨機性的產生,這是算法中成本最高的部分。Fisher-Yates需要接近Nlog2N數位的隨機性,而我們需要90(log2N+N/2)數位,根據我們在Eth2里需要的N值范圍,超出的數位是相當多的?(當N為一百萬時,Eth2大約需要N的兩倍)。
為什么選擇swap-or-not這種算法
如果效率不高,為什么要選擇這個實現?
對單一元素進行混洗
這個算法的閃光點在于,如果我們只關注少數幾個索引,我們不需要對整個列表的混洗進行計算。事實上,我們可以將這個算法用于單個索引,來找出哪個索引將會被替換。
因此,如果我們想知道索引217的元素被混洗到哪里了,我們可以運行只針對該索引的算法,而無需混洗整個列表。此外,相反地,如果我們想知道是什么元素被混洗到索引217,我們可以將算法倒過來運行來找到元素217 (倒過來的意思是從高到低運行輪次,而不是從低到高)。
總之,我們可以在恒定時間內計算出元素?i?被混洗到哪里,也可以計算出元素?i?的源頭在哪里 (用反向操作),計算時間并不取決于列表的長度。Fisher-Yates混洗并不具有這種特性,且不能對單個索引進行混洗,它們往往需要重復混洗整個列表。
在Eth2規范里寫的就是關于如何將算法應用到對單個索引進行混洗。事實上,一次性混洗整個列表只是它的一種優化!如果我們想的話,我們可以輪流只對列表里的一個元素進行混洗:(反向) 運行混洗來找出哪個元素最終落在索引0,再運行一次混洗找出哪個元素最終落在索引1,如此進行下去。
我們不那樣做的原因只是由于決定swap-or-not需要一次性生成一個256位的哈希,且就這樣拋棄255位是很浪費的。如果我們使用1位的哈希或預言,混洗列表中一個元素的效率與混洗整個列表相去無幾。
做到真正的“輕”客戶端
這個特性之所以有意義,原因全在于輕客戶端。輕客戶端相當于是Eth2信標鏈和分片鏈的觀測者,他們不儲存整個狀態,但希望可以安全地訪問鏈上的數據。要對他們的數據正確性進行驗證,即沒有發生欺詐,其中的必要一步就是對證明數據的委員會進行計算。
也就是要用到混洗算法,且我們并不希望輕客戶端必須存儲或是混洗整個驗證者列表。通過swap-or-not混洗,他們可以只對他們需要的一小部分委員會成員進行計算,這樣將在整體上大幅提高效率。
歷史
如果你像我一樣喜歡GitHub的考古特性,你可以在這里查看最初為Eth2尋求混洗算法的討論,這里公布了最后的勝出者。
如果想從另一個角度看swap-or-not混洗算法,可以看一下Protolambda發表的一個更可視化的解釋。
最后
這張圖片是2019年我在EthCC上一邊聽Justin Drake講swap-or-not混洗,一邊在Teku客戶端 (當時它還叫Artemis) 中實現初版swap-or-not混洗。?
作者 | Ben Edgington
1.DeFi總市值:135.5億美元 市值前十幣種漲跌幅,金色財經制圖,數據來源CoinGecko2.過去24小時去中心化交易所的交易量:6.42億美元金色熱搜榜:WAVES居于榜首:根據金色財.
1900/1/1 0:00:00“好人”李春樂 90年的蘇北,每個角落都充滿了故事,亦如今天的李春樂。李春樂,現任職國促會數字科技發展工作委員會副會長,深諳掌握區塊鏈技術對于一個國家經濟發展的重要性,多次強調區塊鏈將掀起新的改.
1900/1/1 0:00:001.DeFi總市值:125.96億美元 市值前十幣種漲跌幅,金色財經制圖,數據來源CoinGecko2.過去24小時去中心化交易所的交易量:7.69億美元金色午報 | 10月7日午間重要動態一覽.
1900/1/1 0:00:00據Filecoin官方消息,Filecoin主網將在epoch 148888正式開啟。預期將在10月15日左右到達這個epoch,然后開始一段時間的監控和解決問題來保證過渡后網絡的正常運行(與預.
1900/1/1 0:00:00不進行硬分叉的話,要如何升級區塊鏈?基于 Substrate 的鏈有一個絕招,可以輕而易舉地做到無分叉升級.
1900/1/1 0:00:009月15日上午,詹克團召開全員大會,針對北京法人再次變更發表以下觀點。他表示已經馬上提起了行政復議,理論上還能變回來。同時北京奧北科技園、深圳工廠兩地正在緊急轉移物資.
1900/1/1 0:00:00


