






 BTC/HKD-0.34%
BTC/HKD-0.34% ETH/HKD-0.59%
ETH/HKD-0.59% LTC/HKD-0.46%
LTC/HKD-0.46% DOT/HKD-0.32%
DOT/HKD-0.32% ADA/HKD-0.77%
ADA/HKD-0.77% SOL/HKD-0.9%
SOL/HKD-0.9% XRP/HKD-0.68%
XRP/HKD-0.68% DOGE/US-0.4%
DOGE/US-0.4%編輯部整理自MEET2021量子位報道|公眾號QbitAI
人工智能,現在發展到什么階段了?
從發展脈絡上看,從符號智能、感知智能,現在應該到認知智能階段了。
或者說,我們正走在認知智能的路上。
今年大火的GPT-3,其參數量已然達到了千億級別,規模已經接近人類神經元的數量了。
這說明,GPT-3的表示能力已經接近人類了,但它仍有一些認知局限——沒有常識。
那我們何時、又將如何走向認知智能?
未來計算機的認知能力,能否超過人類?
什么樣的模型可以驅動未來的認知AI?
認知智能的概念是否又該重新定義?
……
在MEET2021智能未來大會現場,清華大學計算機系教授、系副主任唐杰用簡單、通俗的例子為我們一一解答。

當時聽完演講的觀眾直呼:求唐杰老師的PPT!
關于MEET智能未來大會:MEET大會是由量子位主辦的智能科技領域頂級商業峰會,致力于探討前沿科技技術的落地與行業應用。本次大會現場有李開復等20余位行業頂級大咖分享,500余名行業觀眾參與,超過150萬網友在線收看直播。包括新華社、搜狐科技、澎湃新聞、封面新聞等數十家主流媒體在內紛紛報道,線上總曝光量累計超過2000萬。
亮點
1、認知圖譜有了一個全新概念,它包含三個核心要素:常識圖譜、邏輯生成以及認知推理。
2、GPT-3參數規模已經接近人類神經元的數量,這說明它的表示能力已經接近人類了。但是它有個阿喀琉斯之踵——沒有常識。
3、數據+知識雙重驅動,也許是解決未來認知AI的一個關鍵。
4、用計算模型來解決認知是不夠的,未來需要構建一個真正能夠超越原來的,超越已有模型的一個認知模型。
5、通用人工智能還有多遠?我們希望它有持續學習的能力,能從已有的事實,從反饋中學到新的東西,能處理一些更復雜的任務。
聲音 | 清華大學經濟管理學院金融系教授:發掘區塊鏈潛力警惕多種潛在風險:清華大學經濟管理學院金融系教授、中國金融研究中心主任何平透露,區塊鏈產業勢頭火熱,不斷有新企業涌入賽道。“部分賽道參與者并沒有真正理解什么是分布式存儲,也并沒有理解區塊鏈如何促進商業模式提升。過度投資是區塊鏈產業當前面臨的風險之一。何平強調,市場上打著區塊鏈概念的詐騙行為層出不窮,引發的金融風險不容忽視,對于違法違規行為,監管機構要嚴格執法,懲前毖后,防范龐氏騙局出現。(人民網)[2019/12/6]
為什么是認知圖譜
我給今天的分享起了一個新名字:“認知圖譜:人工智能的下一個瑰寶”。
為什么叫認知圖譜?首先看一下人工智能發展的脈絡。

從最早的符號智能,再到后面的感知智能。最近,所有人都在談論認知智能。
我們現在需要探討“計算機有沒有認知”、“計算機能不能做認知、推理”、“計算機到未來有沒有意識,能夠超過人類”這些問題。
人工智能發展到現在已經有三個浪潮,我們把人工智能叫做三個時代分別是符號AI、感知AI和認知AI,現在正處在實現認知AI的路上。
具體如何實現呢?
我認為需要一些基礎性的東西,比如里面的認知圖譜怎么構建,里面認知的一些邏輯,包括認知的基礎設施怎么建,這也是我們特別想做的一件事情。
回顧機器學習的發展歷程,首先想到的就是很多分類模型,比如決策樹,貝葉斯、神經網絡……
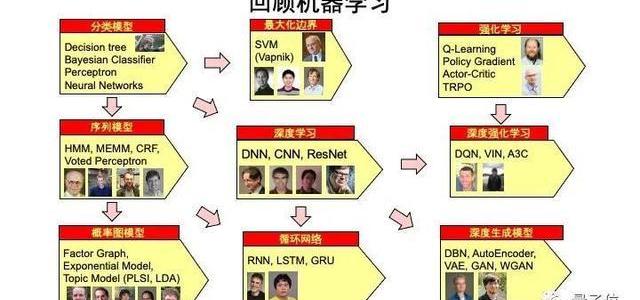
最左邊是分類模型、序列模型、概率圖模型,往右一點是最大化邊界,深度學習,循環智能,隨后是強化學習、深度強化學習,以及最近常提及的無監督學習。
機器思考VS人類思考
機器學習發展到現在,離認知到底還有多遠?
于是,我整理了很多諾貝爾獎和圖靈獎得主的研究,對比了人的認知與機器認知之間的發展模式。
聲音 | 清華大學徐恪:未來區塊鏈會引領新的去中心化世界:據DoNews消息,近日,上海市科委主導的“上海市區塊鏈工程技術中心”成立,清華大學計算機系副主任徐恪教授表示:“區塊鏈還處于一個成長期,很多問題需要解決,很多應用有待挖掘,但是我們確實相信,區塊鏈在未來,會引領一個新的去中心化世界。”[2019/2/20]
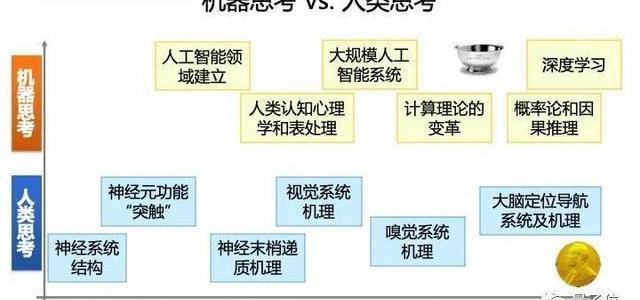
在探究人類思考的歷程里,1900年初才有了神經系統結構的第一次解析,隨后在1932年左右,誕生了一個諾獎級的研究:神經元功能“突觸”。
然后就是神經末梢傳遞機制、視覺系統機理、嗅覺系統機理……直到幾年前,科學家們才探索出人的大腦是如何實現定位導航、以及機理是怎么回事,這也是一個諾獎的研究。

我們來看下機器是如何思考的。
1950年左右,學者創立了人工智能系統,但是1970年左右大家開始拼命去模仿人腦,我們要做一個計算機,讓他跟人腦特別相同。
1990年左右,科學家突然發現其實沒有必要模仿,更多的應該是去參考人腦,參考腦系統,做一個有更多機器思考、機器思維的計算機。
所以在當前這個時代,我們應該用更多的計算機思維,來做計算機的思考,而非人的思考。
因此在這之后,就出現了概率圖模型、概率與因果模型以及深度學習。當然,有人會說,到最后你還在講機器學習,在講一個模型,這個離我們真正的認知智能是不是太遠了?
用計算的方式打造通用人工智能
過去幾年連我自己都不信,我們可以建造一個通用人工智能,讓計算機系統甚至能夠超越人。
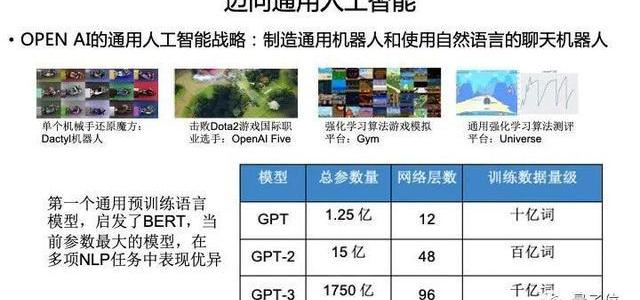
舉一個例子,OpenAI。
兩年前,OpenAI做了**GPT,所有人都覺得只是一個很簡單的語言模型,并不會有什么水花;
去年,GPT升級成GPT-2,15億的參數規模。很多人都可能玩過它的Demo,叫talktotransformer。你可以輸入任何文本,transformer幫你把文本補齊。
聲音 | 清華大學邢春曉:比特幣存在泡沫 但區塊鏈技術上還有很多機會:據同花順財經報道,12月18日,在2018國際區塊鏈數學科學會議上,清華大學信息技術研究院副院長邢春曉發表了題為《區塊鏈賦能智慧社會的研發及應用》的演講,他表示,比特幣等加密貨幣存在泡沫,但區塊鏈技術上還有很多機會。區塊鏈索要建設的理想世界是去中心化、可信、安全、公正、隱私、高效、問責、自治組織和自治社會,但智慧城市和社會的建設面臨諸多挑戰。[2018/12/18]
但在今年6月份的時候,OpenAI發布了一個GPT-3,參數規模一下子達到了1750億,數量級接近人類的神經元的數量。
這個時候給我們帶來了極大的震撼,至少說明GPT-3的表示能力已經接近人類了。
意味著理論上,如果我們能讓計算機參數達到最好,GPT-3可能跟人這種智商表現差不多。
這時候給我們另外一個啟示:
我們到底是不是可以直接通過計算機的結果,也就是計算的方法得到一個超越人類的通用人工智能?
我們來看一下整個模型過去幾年發展的結果,幾乎每年參數規模是10倍左右的增長,右邊的圖給出了自然語言處理中最近幾年的快速變化,幾乎是一個指數級的變化。
可以看到,前幾年變化相對比較小,今年出了GPT-3,谷歌到了6000億的產出規模,明年ds可能還會到萬億級別。所以這是一個非常快速的增長。
現在,則給到我們另外一個問題,
我們到底能不能用這種大規模、大算力的方法,大計算的方法,來實現真正的人工智能呢?

與此同時,也暴露出另一個痛點——成本問題。
GPT-3,如果用單卡的訓練需要355年,整個訓練成本將達到幾億人民幣,一般的公司是做不起來的。
但就算是有互聯網巨頭愿意去做,大家是不是都可以用了?
動態 | 比特大陸向清華大學捐贈設立“數字金融資產研究中心”:鳳凰網商業7月17日訊,近日,清華大學經濟管理學院決定成立數字金融資產研究中心。據悉,此中心為比特大陸向清華大學經濟管理學院捐贈設立,旨在開創數字金融資產新興領域的學術研究,整合世界頂尖的業界和學術資源,為數字金融資產領域的健康發展和制度設計搭建全球領先的研究平臺[2018/7/17]
GPT-3有個阿喀琉斯之踵
不著急。先來看看這樣一個例子,左邊是GPT-3模型,右邊是結果。

第一個是長頸鹿有幾個眼睛?GPT3說有兩個眼睛,沒有問題。
第二個問題,我的腳有幾個眼睛?結果是也有兩個眼睛,這就錯了。
第三個,蜘蛛有幾個眼睛?8個眼睛。
第四個太陽有幾個眼睛?一個眼睛。
最后一個問題,一根草有幾個眼睛?一個眼睛。
可以看到,GPT3很聰明,可以生成所有的結果,但它有個阿喀琉斯之踵——沒有常識。
這時候就需要一個常識的知識圖譜。
2012年,谷歌發出了一個KnowledgeGraph,就是知識圖譜。

當時的概念是,我們利用大量的數據能不能建一個圖譜?于是在未來的搜索中,可以自動把搜索結果結構化,自動的結構化的數據反饋出來。
知識圖譜不僅可以應用到搜索引擎,還可以給計算機帶來一些常識性的知識。
因此,我們是否可以通過這一方法來幫助未來的計算呢?
「數據+知識」驅動未來的認知AI
其實,知識圖譜在很多年前就已經發展起來。
從第一代人工智能——符號AI的時候,就已經開始在做,當時將知識圖譜定義為“符號AI的邏輯表示”。
但到現在也還沒有大規模的發展起來,主要有幾個方面的原因。
清華大學五道口金融學院教授廖理:區塊鏈能夠提高金融系統甚至整個經濟體系的運行效率:清華大學五道口金融學院教授、博士生導師、互聯網金融實驗室主任廖理指出,“區塊鏈的優勢在于能夠用非常低的成本解決網絡交易的身份識別和個人征信,以及使用點對點的交易避免了傳統集中式的清算結構,從而能夠大大提高金融系統甚至整個經濟體系的運行效率。廖理同時指出,區塊鏈將成為互聯網金融夢想照進現實的關鍵技術。但是,現在的區塊鏈還處在嬰兒時期,各方面的基礎設施還很不完善,而這種不完善限制了區塊鏈的大規模應用。[2018/3/18]
第一,構建的成本非常的高。
CYC,最早的知識圖譜之一,負責定義知識斷言。
簡單來說就是,一個ABC三元組,A就是主體,B就是關系,C是受體。
比如,人有手,人就是主體,有就是關系,手就是受體。
這么一個簡單的問題,成本就在5.7美元。
第二,自動構建精度很低。
另一個典型的知識圖譜NELL,互聯網完全自動方法的生成出來,但錯誤率一下子提高到10倍。
這兩個項目目前基本上都處于半停滯狀態。

于是,我們現在就在思考,若是將上述兩種方式結合在一起,是否能夠驅動認知AI?
第一,從大數據的角度,做數據驅動。用深度學習舉十反一的方法,把所有的數據進行建模,并且學習數據之間的關聯關系,學習數據的記憶模型。
第二,我們要用知識驅動,構建一個知識圖譜,用知識驅動整個事情。
我們把兩者結合起來,這也許是解決未來認知AI的一個關鍵。
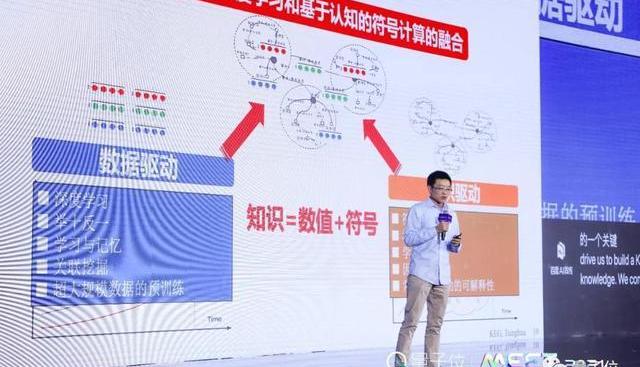
當然這些也還不夠。我們的未來是需要構建一個真正能夠超越原來的、已有模型的一個認知模型。
我們需要一個全新的架構框架,也需要一個全新的目標函數,這時候才有可能超過這樣的預訓練模型,否則就是在跟隨GPT-3。
而放在眼下要做的,就是讓機器有一定的創造能力,光文本還不夠,我們希望創造出真正的圖片,它是創造,不是查詢。
比如,機器可以通過文字,將原有的圖片生成新的圖片。
當然,光創造還不夠,我們離真正通用的人工智能還有多遠?
我們希望真正的通用人工智能有持續學習的能力,能夠從已有的事實,從反饋中學習到新的東西,能夠完成一些更加復雜的任務。
認知AI的九準則
這時候,再回到起初最基本的問題:什么叫認知?
只要有可持續學習的能力就是認知嗎?
如果這樣的話,GPT-3也有持續學習的能力,知識圖譜也有學習的能力,因為它在不停的更新。
如果能完成一些復雜任務就是認知嗎?
也不是,我們已經有些系統已經可以完成非常復雜的問題。

那什么是認知呢?
最近,通過我們的一些思考,定義了認知AI的九準則。這九個準則是我從人的認知和意識中抽象出來的九個準則。
第一個,叫適應與學習能力。
比如說今天MEET大會,機器人自動學習,可以知道在這個特定的場景下應該做什么事情。
第二個,叫定義與語境能力。
模型能夠在特定語境下感知上下文,對環境有一定的感知能力。
第三個,叫自我系統的準入能力。
機器能夠自定義什么是我,什么是非我,這叫人設。如果這個機器能知道自己的人設是什么,那么我們認為它有一定的認知能力。
第四個,優先級與訪問控制能力。
在一定的特定場景下它有選擇的能力。我們人都可以在雙十一選擇購物,如果機器在雙十一的時候能選擇我今天想買點東西,明天后悔了,不應該買。
這時候機器有一定的優先級和訪問控制。
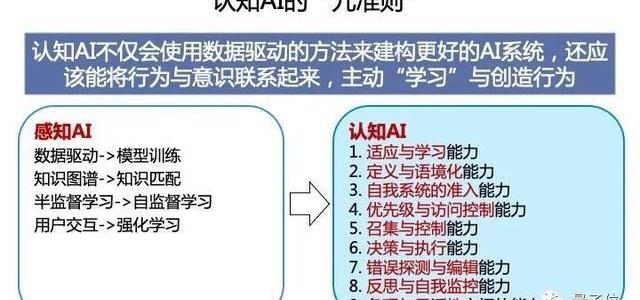
第五個,召集與控制能力。這個機器應該有統計和決策的能力。
第六個,決策與執行能力,機器人在感知到所有的數據以后可以做決策。
第七個,錯誤探測與編輯能力。
這個非常重要,人類的很多知識都在試錯中發現的。比如現在學的很多知識,我們并不知道什么知識是最好的。
我們需要不停的試錯,也許我們今天學到了1+1=2是很好,但是你嘗試1+1=3,1+1=0,是不是也可以呢?你嘗試完了發現都不對,這叫做錯誤探測與編輯,讓機器具有這個能力,非常地重要。
第八個,反思與自我控制、自我監控。
如果這個機器人在跟你聊天的過程中,聊了很久,說“不好意思我昨天跟你說的一句話說錯了,我今天糾正了。”這時候機器具有反思能力。
最后,這個機器一定要有條理和理性。
一個面向認知的AI架構
在九個準則的基礎上,我們提出了一個全新的認知圖譜的概念。
主要有三個核心要素。
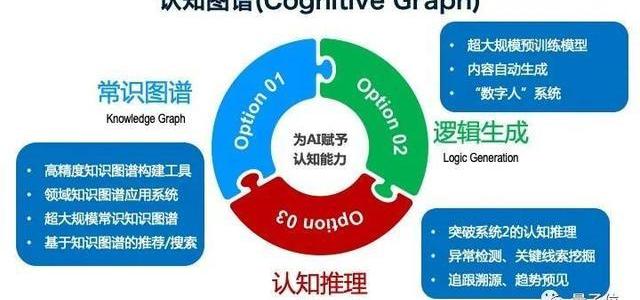
第一個,常識圖譜,這與知識圖譜的幾個要素非常相關。比如說高精度知識圖譜的構建、領域知識圖譜的應用系統、超大規模知識圖譜的構建,還有基于知識圖譜的搜索和推薦,這是傳統的一些東西。
第二個,邏輯生成。這需要超大規模的預訓練模型,并且能夠自動進行內容生成。同時我們在未來可以構建一個數字人的系統,它能夠自動的在系統中,能夠生成相關的東西,能夠做得像人一樣的數字人。
第三個,認知推理。讓計算機有推理、有邏輯的能力。
這時候說起來比較虛,用人的認知來通俗理解一下。
人的認知有兩個系統,一個叫系統1,一個叫系統2。
系統1就是計算機做的匹配。
你說,清華大學在哪?它便立刻匹配出來北京。
但如果你要是問,清華大學在全球計算機里到底排第幾?以及為什么是這個名次?
這時候計算機就回答不了,這就需要一定的邏輯推理,也就是系統2所做的事情。
當前所有的深度學習都是做系統1,解決了系統1問題——直覺認知,而不是邏輯認知。
因此在未來,我們要做更多關于系統2的事情。

從腦科學來看,相對現在做的事情有兩個最大的不同,第一,就是記憶,第二就是認知推理。
記憶是通過海馬體實現,認知是前額葉來實現。這兩個系統非常關鍵,如何實現呢?
我們看記憶模型,巴德利記憶模型分三層,短期記憶就是一個超級大的大數據模型。
在大數據模型中,我們怎么把大數據模型中有些信息變成一個長期記憶變成我們知識,這就是記憶模型要做的事情。
那認知模型呢?我們構建了一個面向認知的AI架構。
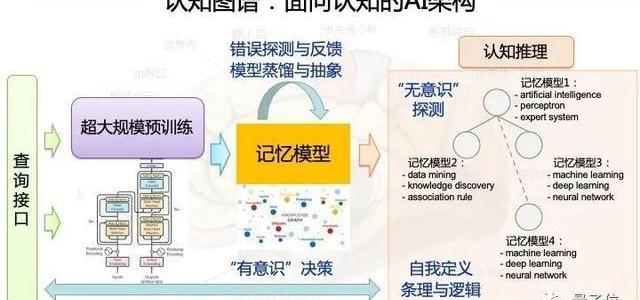
這個框架左邊是一個查詢接口,這是輸入,也可以說成是用戶端。
中間是一個超大規模的預訓練模型,然后是一個記憶模型。
記憶模型通過試錯、蒸餾,把一些信息變成一個長期記憶存在長期記憶模型中。
長期記憶模型中會做無意識的探測,也會做很多自我定義和條理的邏輯,并且做一些認知的推理。
在這樣的基礎上我們構建一個平臺。最終目標是打造一個知識和認知推理雙輪驅動的一個框架。底層是分布式的存儲和管理,中間是推理、決策、預測,再上面是提供各式各樣的API。
好,我今天大概就把我們的理念和想法給大家介紹一下,如果大家有興趣的話,可以查閱我們更多的信息。
謝謝大家!
Tags:GPT人工智能MEETGPT價格GPT幣人工智能技術應用學人工智能后悔死了人工智能考研考哪些科目MEET價格MEET幣
FX168財經報社(北美)訊周四,比特幣一度上漲,突破5萬美元,這是加密貨幣行業看漲的新跡象,區塊鏈數據顯示,一些大投資者開始囤積長期貨幣.
1900/1/1 0:00:00比特幣在過去一年中漲勢迅猛,本周更是站上52000美元。就在這個歷史性時刻,全球首只比特幣ETF也在周四于多倫多交易所正式推出.
1900/1/1 0:00:00美國銀行分析師弗朗西斯科·布蘭奇抨擊Billions項目組是“異常波動”,“不切實際”和對環境造成災難性的資產,這些資產對儲備財富或通脹對沖毫無用處.
1900/1/1 0:00:00有先鋒計算pi幣量方法不正確,得出錯誤的結論,比如人均基礎幣1000個,而人均總幣量卻能達到4000,這犯了常識性錯誤,很多先鋒誤將人均挖礦速度估算成自己挖礦速度中間某一個值,導致計算錯誤.
1900/1/1 0:00:00美女壁紙圖片:超美金牌小廚娘申請出戰 Memeland公布MEME代幣空投數量,總計172.5億枚:金色財經報道,NFT項目Memeland在官推公布了MEME代幣空投數量,總計172.5億枚.
1900/1/1 0:00:00近日,特斯拉對外事務副總裁陶琳表示,在售ModelY價格上調8000元人民幣,即日生效。已訂購客戶不受此次調價影響.
1900/1/1 0:00:00


