






 BTC/HKD+0.38%
BTC/HKD+0.38% ETH/HKD+0.12%
ETH/HKD+0.12% LTC/HKD+0.19%
LTC/HKD+0.19% DOT/HKD+0.61%
DOT/HKD+0.61% ADA/HKD-1.13%
ADA/HKD-1.13% SOL/HKD+0.92%
SOL/HKD+0.92% XRP/HKD-0.55%
XRP/HKD-0.55% DOGE/US-0.21%
DOGE/US-0.21%許振文
騰訊游戲
增值服務部后臺開發組組長
從事游戲大數據相關領域8年多,負責游戲數據分析平臺iData的架構設計和關鍵模塊開發,為騰訊超過400款游戲提供高效快速的數據分析服務。
中國通信研究院發布的微服務行業標準和分布式消息隊列技術標準的核心制定者之一,Linux內核之旅開源社區的負責人,Istio社區Member。
在分布式存儲,調度、多維數據分析、實時計算、事件驅動決策系統、微服務、ServiceMesh領域有豐富的實戰經驗。
大家好我是許振文,今天分享的主題是《基于Flink+ServiceMesh的騰訊游戲大數據服務應用實踐》,主要會分為以下四個部分進行分享:
背景和解決框架介紹
實時大數據計算OneData
數據接口服務OneFun
微服務化&ServiceMesh
一、背景和解決框架介紹
1、離線數據運營和實時數據運營

首先介紹下背景,我們做游戲數據運營的時間是比較久的了,在13年的時候就已經在做游戲離線數據分析,并且能把數據運用到游戲的運營活動中去。
但那時候的數據有一個缺陷,就是大部分都是離線數據,比如今天產生的數據我們算完后,第二天才會把這個數據推到線上。所以數據的實時性,和對游戲用戶的實時干預、實時運營效果就會非常不好。尤其是比如我今天中的獎,明天才能拿到禮包,這點是玩家很不爽的。
現在提倡的是:“我看到的就是我想要的”或者“我想要的我立馬就要”,所以我們從16年開始,整個游戲數據逐漸從離線運營轉到實時運營,但同時我們在做的過程中,離線數據肯定少不了,因為離線的一些計算、累計值、數據校準都是非常有價值的。
實時方面主要是補足我們對游戲運營的體驗,比如說在游戲里玩完一局或者做完一個任務后,立馬就能得到相應的獎勵,或者下一步的玩法指引。對用戶來說,這種及時的刺激和干預,對于他們玩游戲的體驗會更好。
其實不單單是游戲,其他方面也是一樣的,所以我們在做這套系統的時候,就是離線+實時結合著用,但主要還是往實時方面去靠攏,未來大數據的方向也是,盡量會往實時方向去走。
2、應用場景
1)游戲內任務系統
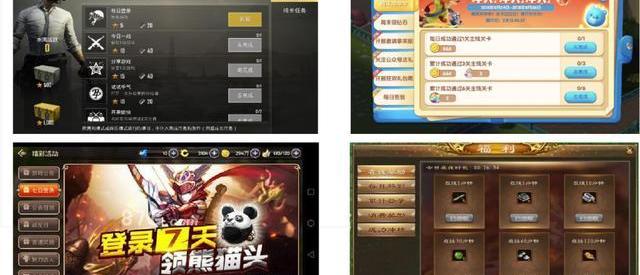
這個場景給大家介紹一下,是游戲內的任務系統,大家都應該看過。比如第一個是吃雞里的,每日完成幾局?分享沒有?還有其他一些活動都會做簡歷,但這種簡歷我們現在都是實時的,尤其是需要全盤計算或者分享到其他社區里的。以前我們在做數據運營的時候,都是任務做完回去計算,第二天才會發到獎勵,而現在所有任務都可以做到實時干預。
游戲的任務系統是游戲中特別重要的環節,大家不要認為任務系統就是讓大家完成任務,收大家錢,其實任務系統給了玩家很好的指引,讓玩家在游戲中可以得到更好的游戲體驗。
2)實時排行版
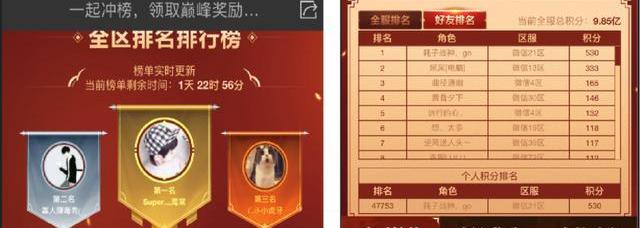
還有一個很重要的應用場景就是游戲內的排行榜,比如說王者榮耀里要上星耀、王者,其實都是用排行榜的方式。但我們這個排行榜可能會更具體一些,比如說是今天的戰力排行榜,或者今天的對局排行榜,這些都是全局計算的實時排行榜。而且我們有快照的功能,比如0點00分的時候有一個快照,就能立馬給快照里的玩家發獎勵。
這些是實時計算的典型應用案例,一個任務系統一個排行榜,其他的我們后面還會慢慢介紹。
3、游戲對數據的需求
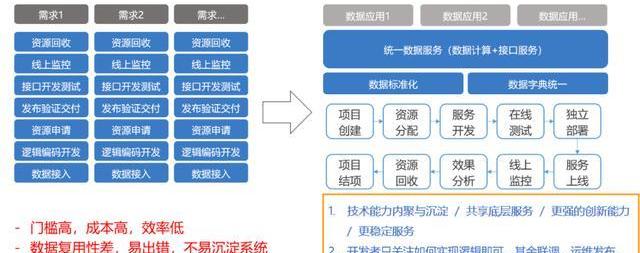
再說一下為什么會有這樣一個平臺,其實我們最初在做數據運營的時候,是筒倉式或者手工作坊式的開發。當接到一個需求后,我們會做一個資源的評審、數據接入、大數據的編碼,編碼和數據開發完后,還要做線上資源的申請、發布、驗證,再去開發大數據計算完成后的服務接口,然后再開發頁面和線上的系統,這些都完了后再發到線上去,做線上監控,最后會有一個資源回收。
日本任命此前專門處理加密貨幣等問題的Kuritato Teruhisa為日本金融廳負責人:金色財經報道,據日經新聞報道,日本政府計劃提拔Kuritato Teruhisa為日本金融廳負責人,取代現任的Junichi Nakajima。Kuritato Teruhisa現年59歲,現任日本金融廳下轄專門處理加密貨幣及金融科技問題的戰略發展和管理局局長。[2023/6/27 22:02:43]
其實這種方式在很早期的時候是沒有問題的,那為什么說現在不適應了?主要還是流程太長了。我們現在對游戲運營的要求非常高,比如說我們會接入數據挖掘的能力,大數據實時計算完成之后,我們還要把實時的用戶畫像,離線畫像進行綜合,接著推薦給他這個人適合哪些任務,然后指引去完成。
這種情況下,原來的做法門檻就比較高了,每一個都要單獨去做,而且成本高效率低,在數據的復用性上也比較差,容易出錯,而且沒有辦法沉淀。每一個做完之后代碼回收就扔到一塊,最多下次做的時候,想起來我有這個代碼了可以稍微借鑒一下,但這種借鑒基本上也都是一種手工的方式。
所以我們希望能有一個平臺化的方式,從項目的創建、資源分配、服務開發、在線測試、獨立部署、服務上線、線上監控、效果分析、資源回收、項目結項整個綜合成一站式的服務。
其實這塊我們是借鑒DevOps的思路,就是你的開發和運營應該是一個人就可以獨立完成的,有這樣一個系統能夠去支撐這件事。當一個服務在平臺上呈現出來的時候,有可能會復用到計算的數據,比說實時的登錄次數或擊殺數,那這個指標在后面的服務中就可以共用。
而且有了這樣一個平臺之后,開發者只需主要關注他的開發邏輯就行了,其余兩條運維發布和線上運營都由平臺來保證。所以我們希望有一個平臺化的方式,把數據計算和接口服務統一起來,通過數據的標準化和數據字典的統一,能夠形成上面不同的數據應用,這個是我們的第一個目標。
其實我們現在都是這種方式了,第一是要在DevOps的指導思想下去做,尤其是騰訊去做的時候數據服務的量是非常大的,比如我們去年一共做了5、6萬的營銷服務,在這種情況下如果沒有平臺支撐,沒有平臺去治理和管理這些服務,單靠人的話成本非常大。
4、思路
3個現代化,大數據應用的DevOps。
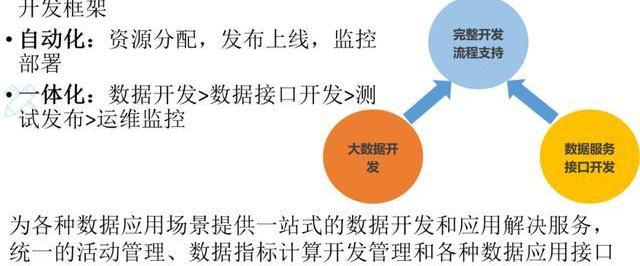
我們的思路也是這樣,三個現代化,而且把大數據應用的DevOps思路實現起來。
規范化:流程規范、數據開發規范和開發框架;
自動化:資源分配、發布上線、監控部署;
一體化:數據開發、數據接口開發、測試發布、運維監控。
所以我們針對大數據的應用系統,會把它拆成這樣三塊,一個是大數據的開發,另外一個是數據服務接口的開發,當然接口后面就是一些頁面和客戶端,這些完了后這些開發還要有一個完整的開發流程支持。
這樣我們就能夠為各種數據應用場景提供一站式的數據開發及應用解決服務、統一的活動管理、數據指標計算開發管理和各種數據應用接口自動化生產管理的一站式的服務。
這樣的系統能保障這些的事情,而且我們這里也合理拆分,不要把大數據和接口混到一塊去,一定要做解耦,這是一個非常關鍵的地方。
5、數據服務平臺整體架構
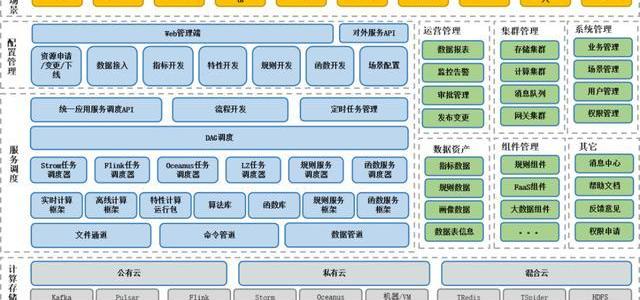
1)計算存儲
這個框架大家可以看一下,我認為可以借鑒,如果你內部要去做一個數據服務平臺的話,基本上思路也是這樣的,底層的Iass可以不用管,直接用騰訊云或者阿里云或者其他云上的服務就可以了。
我們主要是做上層這一塊的東西,最下面的計算存儲這個部分我們內部在做系統的時候也不是care的,這塊最好是能承包出去。現在Iass發展到這個程度,這些東西在云上可以直接像MySQL數據庫或者Redis數據庫一樣購買就行了,比如Kafka、Pulsar、Flink、Storm。
存儲這塊我們內部的有TRedis、TSpider,其實就是Redis和MySQL的升級版本。基礎這塊我建議大家如果自己構建的話,也不需要太過于關注。
2)服務調度
系統核心主要是在中間的服務調度這個部分,它是統一的調度API,就是上層的一些服務能發下來,然后去統一調度。另外一個就是流程的開發,我們有一個不可缺少的調度系統,這里我們使用的是DAG調度引擎,這樣我們可以把離線任務、實時任務、實時+離線、離線+函數接口的服務能夠組合起來,來完成更復雜實時數據應用場景。
Aptos原生代幣APT上市首周交易量逾13億美元:金色財經報道,根據CoinGecko的數據,Aptos區塊鏈原生代幣APT自周三首個完整交易日以來已完成至少13億美元的交易量,截至發稿時APT的交易價格為7.38美元,比最高價相比下跌了46%,當前市值約為9.63億美元。
此外,交易所Binance占APT每日現貨交易量的一半以上,截至發稿時,在過去24小時內,幣安平臺五個APT交易對的交易量為1.93億美元。[2022/10/22 16:35:20]
比如我們現在做的實時排行榜,把實時計算任務下發到Flink后,同時會給Flink下發一個URL,Flink拿到URL后,它會把符合條件的數據都發送到URL,這個URL其實就是函數服務,這些函數服務把數據,在Redis里做排序,最終生成一個排行榜。
再往下的這個調度器,你可以不斷地去橫向拓展,比如我可以做Storm的調度器、Flink的調度器、Spark的調度器等等一系列。在這塊可以形成自己算法庫,這個算法庫可以根據場景去做,比如有些是Flink的SQL的分裝,也就是把SQL傳進來,它就能夠計算和封裝的Jar包。另外比如一些簡單的數據出發、規則判斷也可以去做,直接把算法庫分裝到這塊就行。
其實這塊和業務場景沒有直接關系的,但算法庫一定是和場景是有關系的,另外下層我們會有寫文件通道,比如說一些jar包的分發,這里騰訊用的是COS,能夠去做一些數據的傳輸和Jar包的提交。
還有一個命令管道,它主要針對機器,比如提交Flink任務的時候一定是通過命令管道,然后在一臺機器去把Jar包拉下來,然后同時把任務提交到Flink集群里去。數據管道也是類似的一個作用。
3)各種管理
另外還要將一個蠻重要的內容,右邊綠色這塊的運營監控、集群管理、系統管理,還有消息中心、幫助文檔,這些都是配套的,整個系統不可缺少的。
還有一部分是組件管理,包括大數據組件管理、函數管理、服務的二進制管理都可以在這里能夠做統一的管理。
數據資產,比如我們通過Flink或者Storm能夠生成的數據指標,它的計算邏輯的管理都在這里面,包括我們計算出來后,把這些指標打上標簽或者劃后,我們也作為數據資產。
還有一個最重要的是數據表的管理,我們無論是Flink或Storm,它的計算最終的落地點一定是通過一個數據表能算出來的。其他都還好,數據報表,比如每天計算多少數據,成功計算多少,每天有多少任務在跑,新增多少任務,這些都在里面可以做,包括我們版本的發布變更。
還有一個是外部管理端,這個根據業務場景去做就行了,等會演示我們管理端的時候大家就可以看到,其實我們的菜單相對來說比較簡單,根據比如我們的數據接入,從源頭把數據接入到Kafka或者Pulsar里去。然后數據指標基于接入的數據表,進行數據指標的計算,比如一些特性的Jar包,它是多張表的數據混合計算,或者是加上的表的混合計算,等等一系列通過硬場景做的一些分裝。
我們最終把這些做完后,所有的大數據都是通過對外的服務API暴露出去的,比如最終游戲任務是否完成,用戶ID過來后我們能看這個用戶的任務是否完成,這樣的一些應用場景可以直接使用API去操作。
這是整個流程,講得比較細后面大家才會更清晰。
二、實時大數據計算OneData
1、數據開發流程
這是我們整體的數據應用流程:
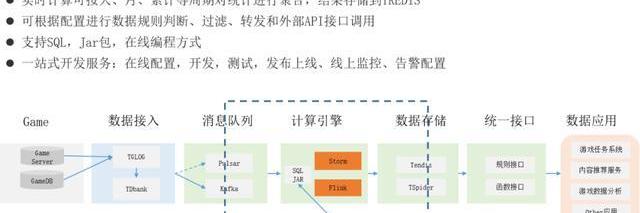
我們的GameServer先把數據上傳到日志Server,日志Server再把數據轉到Kafka或者Pulsar,就是消息隊列里。
接進來后是數據表,數據表是描述,基于描述的表去開發指標、數據。比如我們這里一共有三類,一類是SQL,另外一類是我們已經分裝好的框架,你可以自己去填充它的個性代碼,然后就可以在線完成Flink程序的編寫。
還有一種是自己全新的在本地把代碼寫好,再發到系統里去調測。之前說了在大數據計算和數據接口一定要做解耦,我們解耦的方式是存儲,存儲我們用Redis。它這種做法是把Redis和SSD盤能夠結合起來,然后再加上RockDB,就是Redis里面它hold熱點數據,同時它把這些數據都通過這個RockDB落地到SSD盤里去,所以它的讀寫性非常好,就是把整個磁盤作為數據庫存儲,而不像普通的Redis一樣再大數據情況下智能把內存作為存儲對象。
7月新注冊ENS域名數超37萬,創歷史新高:8月1日消息,據DuneAnalytics的數據顯示,7月新注冊ENS域名數為378,442個,超過此前5月創下的最高記錄,365,652個,創歷史新高。[2022/8/1 2:51:05]
在大數據把數據計算存儲進去后,后面的就簡單了,我們提供查詢的服務有兩種,一種是計算的指標,點一下就可以生成接口,我們叫規則接口;然后我們另外一種,也提供特性化的存儲到介質里,我可以自己去定義他的SQL或者查詢方式,然后在數據進行加工處理,生成接口。
還有一種方式,是我們在Flink和Storm直接把數據配置我們這邊的一個函數接口,比如我剛才講的排行榜的方式,就給一個接口,他直接在Flink這邊處理完成之后,把數據吐到函數接口里面,函數接口對這個數據進行二次處理。
這個是整個處理方式,所以我們前面講的就是,基于Flink和Storm構建一個全面的、托管的、可配置化的大數據處理服務。主要消費的是Kafka的數據,Pulsar現在在少量的使用。
這樣做就是我們把數據的開發門檻降低,不需要很多人懂Flink或者Storm,他只要會SQL或者一些簡單的邏輯函數編寫,那就可以去完成大數據的開發。
2、數據計算統一
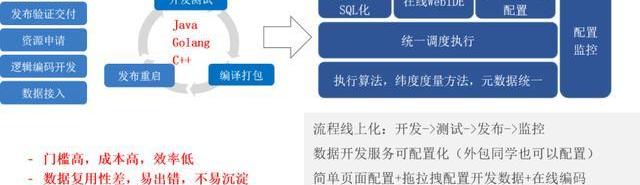
其實我們之前在做的時候,有一些優化的過程,原來每一個計算任務都是用Jar包去寫,寫完之后就是編輯、打包、開發、發布。后來我們劃分了三種場景,一種是SQL化,就是一些我們能用SQL表示的我們就盡量分裝成SQL,然后有一個Jar包能去執行這個提交的SQL就可以了。
還有一種是在線的WebIDE,是處理函數的邏輯,舉例子Storm里可以把blot和spout暴露出來,你把這兩函數寫完后,再把并行度提交就可以運行。但這里我們具體實現的時候是基于Flink去做的。
另一個是場景化的配置,我們個性化的Jar包能夠統一調度,根據調度邏輯去執行。
3、數據計算服務體系
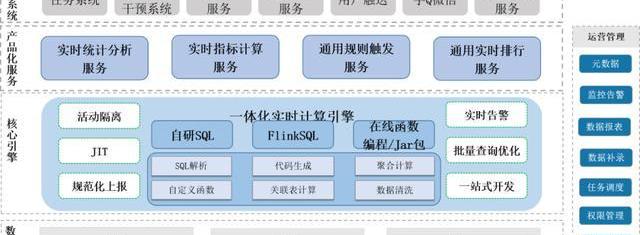
這是我們整個OneData計算體系的過程,支持三種,一種的自研的SQL,一種是FlinkSQL,還有是Jar包。
我們自研的SQL是怎么存儲,最早是使用Storm,但StromSQL的效率非常低,所以我們根據SQLParser做的SQL的分裝,我們對SQL自己進行解析,自己形成函數,在SQL提交之后,我們用這樣的方式直接把它編譯成Java的字節碼,再把字節碼扔到Strom里去計算。
Flink這塊我們也繼承了這種方式,后面會講一下兩種方式有什么區別。其實我們自研SQL在靈活性上比FlinkSQL要好一點。
這里是做平臺化,不能說直接放一個FlinkSQL去跑,因為我們想要在里面統計整個業務邏輯的執行情況,比如SQL處理的數據量,正確的和錯誤的,包括一些衰減,都是要做統計。
這是基本的過程,完了后我們在上面形成的一些基本場景,比如實時統計的場景,PV,UV,用獨立的Jar包去算就行了,配置一下表就可以去計算。另外實時指標的服務,比如殺人書,金幣的積累數,游戲的場次,王者榮耀里下路走的次數,這種數據都可以作為實時指標。
還有一種是規則觸發服務,表里的某個數據滿足什么條件時,觸發一個接口。還有通訊實時排行榜和一些定制化的服務。
1)自研SQL
接下來說我們自研SQL的過程,我們早期為了避免像Hive一樣,而我們自己通過SQLPaser的語法抽象后,把它生成一段函數,就不需要這么多的對賬調用。
這個是函數生成過程,最終生成的就是這樣一段代碼,它去做計算邏輯,一個函數完成,不需要函數棧的調用,這樣效率就會大大提升。我們原來單核跑八萬,放在現在可以跑二十多萬。
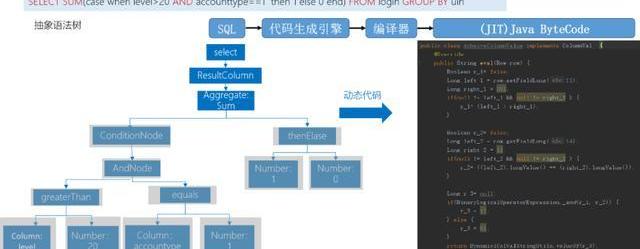
整個處理的時候,我們把sql編譯成字節碼,Flink消費了數據后,把數據轉化成sql能夠執行的函數,就是roll的方式。然后把Roll整個數據傳到class里去執行,最后輸出。
Virtu Financial為其Crypto交易團隊招聘一名周末加密交易員:7月6日消息,高頻交易和做市公司Virtu Financial正在為其Crypto交易團隊招聘一名周末加密交易員。此次招聘反應了加密貨幣24/7交易的獨特性。
招聘公告顯示,CryptoTrader是風險管理人員,有助于保持我們的交易系統和策略平穩運行,提供關鍵的運營支持并維護我們的高性能算法交易策略。職責包括監督和優化戰略績效、日內市場和信用風險管理、基本的后臺和站點可靠性監控等。[2022/7/6 1:53:38]
這種場景適合于,比如flinksql它有狀態值,我們要統計某個最大值的話,要一直把用戶的最大值hold到內存里去。而我們自研的SQL呢,自己寫的函數,它把數據借助第三方存儲,比如剛才說的TRedis存儲。每次只需要讀取和寫入數據即可,不需要做過多的內存的hold。
當前做到狀態的實時落地,就算掛掉也能立馬起來接著去執行,所以超過10G、100G的數據計算,都不成問題,但是Flinksql如果要算的話,它的狀態值就一直要hould到內存里去了,而且掛掉后只能用它的checkpoint去恢復。
所以這是這兩種SQL的應用場景。
2)SQL化

另外SQL里我們還可以做些其他的事情。我們的數據是持久化保存在存儲里的,那存儲里如果是同一張表,同一個緯度,比如我們都是用QQ,在這個緯度上我們配置了兩個指標,那能不能一次算完?只消費一次把數據算完,然后存儲一次。
其實這種在大數據計算里是很多的,目前在我們在做的平臺化就可以,比如一個是計算登錄次數,另一個是計算最高等級,這兩個計算邏輯不一樣,但是消費的數據表是一樣的,然后聚合緯度也是一樣的,聚合關鍵字也是一樣。那這個數據就可以進行一次消費,同時把數據計算出來同時去落地,大大減少了存儲和計算成本。
我們現在整個游戲里面有一萬一千多個指標,就是計算出來的,存儲的緯度有兩千六百多,實際節省計算和存儲約有60%以上。
兩個SQL,甚至更多的SQL,我們一張表算十幾個指標很正常,原來要消費十幾次現在只需要一次就可以算出來。而且這種情況對用戶是無感知的。A用戶在這張表上配了指標是A緯度,B用戶在這張表上配了指標也是A緯度,那這兩個用戶的數據,我們在底層計算的時候就消費一次計算兩次存儲一次,最終拿到的數據也是一樣的。
3)在線實時編程
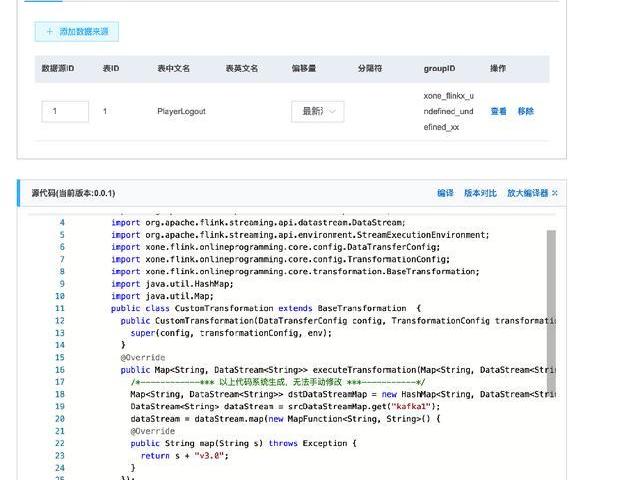
無需搭建本地開發環境;
在線開發測試;
嚴格的輸入輸出管理;
標準化輸入和輸出;
一站式開發測試發布監控。
再介紹下剛才提到的在線實時編程,其實很多時候對開發者來說,搭建一個本地的Flink集群做開發調測也是非常麻煩的,所以我們現在就是提供一種測試環境,上層的代碼都是固定的,不能修改。比如數據已經消費過來了,進行數據的加工處理,最終往存儲里去塞就可以了。
通過這種方式,我們可以對簡單邏輯進行分裝,需要函數代碼,但比SQL復雜,比自動的Jar包開發要簡單一些,可以在線寫代碼,寫完代碼直接提交和測試就能完成結果的輸出。而且這種的好處是,數據的上報邏輯,數據的統計邏輯,我都在這里面分裝好了。只要管業務邏輯的開發就好了。
4、Flink特性應用
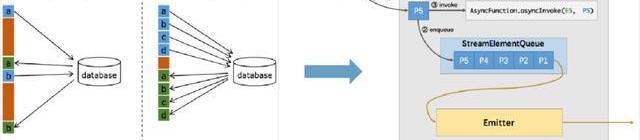
時間特性:基于事件時間水印的監控,減少計算量,提高準確性;
異步化IO:提高吞吐量,確保順序性和一致性。
我們最早在Strom里做的時候,數據產生的時間和數據進到消息隊列的時間,都是通過這種消息里自帶的時間戳,每一個消息都是要對比的。有了Flink之后,有了watermark這個機制之后,這一部分的計算就可以減少了。
實際測試下來的效果也是比較理想的,我們原來在Storm里單核計算,大概是以前的QPS,加上讀寫和處理性能,單核五個線程的情況下。但是Flink的時候我們可以到一萬,還加上Redis存儲IO的開銷。
BTC損失地址數達到歷史新高:金色財經報道,據Glassnode數據顯示,BTC損失地址數剛剛達到歷史新高,7日均值數額為18,959,514.625。[2022/7/5 1:50:54]
另一個我們原來數據想要從Redis里取出來,再去算最大值最小值,完了算了再寫到Redis里,這個都是同步去寫的,但是同步IO有一個問題就是性能不高。
所以我們現在在把它改成異步IO,但是異步IO也有個特點就是整個一條數據的處理必須是同步的,必須先從Redis里把數據取出來,然后再把值計算完,再塞到里面去,保證塞完后再處理下一個統一的數據。
我們再做這樣的一些優化。Flink這里有些特性可以保證我們數據的一致性,而且提升效率。
5、統一大數據開發服務—服務案例
接著介紹下更多的案例,如果大家玩英雄聯盟的話,那這個任務系統就是我們設計的,下次玩做這個任務的時候,你就可以想起我。還有天龍八部、CF、王者榮耀LBS榮耀戰區、王者榮耀的日常活動、有哪些好友是實時在線的,跟你匹配的。
三、數據接口服務OneFun
1、數據應用的出口
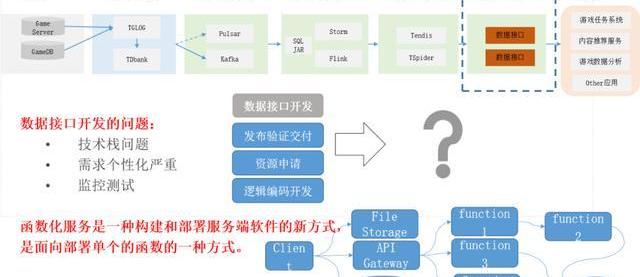
下面介紹下函數,我們原來在做的時候也是存在著一些問題,把數據存到存儲里面,如果存儲直接開放出去,讓別人任意去使用的話,其實對存儲的壓力和管理程度都是很有問題的。所以后來我們采用了一種類似于Fass的的解決方式。我們把存儲在里面的元數據進行管理,完了之后接口再配置化的方式,你要使用我這個DB,這個DB最大QPS多少,我就進行對比,允許你之后才能使用這個量。
比如我這個DB的最大QPS只有10萬,你要申請11萬,那我就給你申請不了,我就只能通知DB把這個Redis進行擴容,擴容后才給你提供使用。
所以這里面牽扯到我們的指標數據的元數據管理和接口之間的打通。
2、一體化函數執行引擎—OneFun
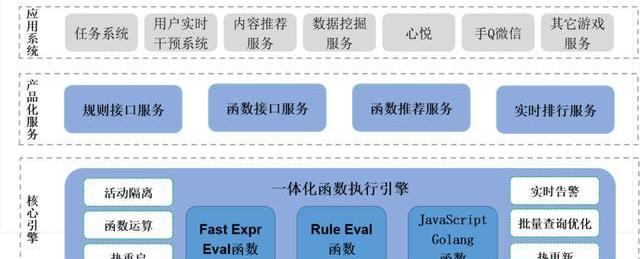
這個和剛才OneData的方式是一樣的,比如這塊提供了快速的函數,還有一些在線函數編程的方式的接口,你可以在上面寫一點JavaScript或者Golang代碼,然后就生成接口,接口里面可以直接對外提供服務,把他形成產品化的包裝,在上層根據接口衍生出更多其他的一些應用系統。
3、基于ssa的在線golang函數執行引擎

這里重點介紹下golang,其實我們是基于golang語言本身ssa的特點去做的,我們有一個執行器,這個執行器已經寫好的,它的作用就是可以把你寫的golang代碼提交過來,加載到它的執行器里。
并且我們可以把我們寫的代碼作為函數庫,積累下來然后放進去,它可以在執行的時候去調用這些函數庫,而這里面寫的代碼語法和golang是完全一樣的。
同時我們在這里面執行的時候,指定了一個協程,每一個協程我們規定它的作用域,就是以沙箱機制的方式來去執行,最先實現的就是外部context去實現的,我們就可以實現web化的golang開發,這種有點像lua那種腳本語言一樣,你在線寫完語言直接提交執行。
4、基于V8引擎的在線函數服務引擎
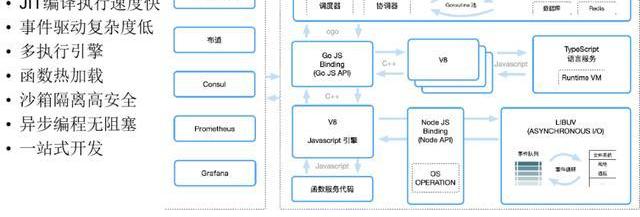
這是我們的javascript的執行引擎,我們主要是做了V8引擎的池子,所有javascript寫完之后,丟到V8引擎上去執行,這應該大家都能夠理解,如果大家玩過JS的可以理解這種方式,就是V8引擎里直接去執行。
5、一體化函數執行引擎--函數即服務
這是我們的在線函數編寫過程:
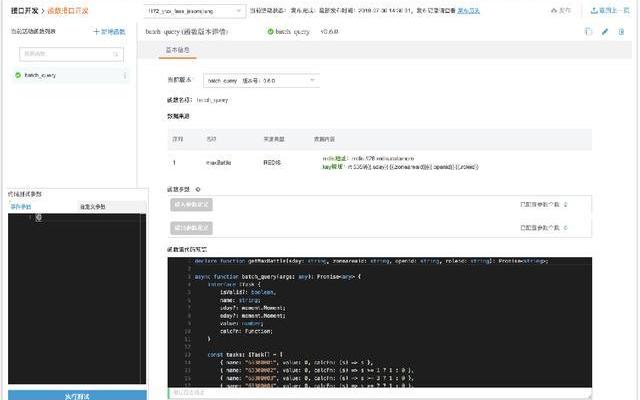
右下角是我們的函數代碼編寫區,寫完后左邊的黑框是點擊測試,輸出可以在這里寫,點擊測試就會把結果輸出出來,通過這種方式,我們極大地擴張了我們數據平臺的開發能力。原來是本地要把golang代碼寫完,然后調試完再發到線上環境去測試,而現在我們可以很大的規范化,比如說數據源的引入,我們就直接可以在這里去規定了,你只能引入申請過的數據源,你不能隨便亂引入數據源,包括你數據源引入的時候,QPS放大我都可以通過這種方式知道。
降低啟動成本;
更快的部署流水線;
更快的開發速度;
系統安全性更高;
適應微服務架構;
自動擴展能力。
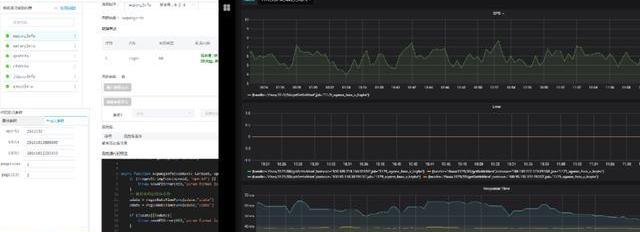
這個是我們一站式,把函數開發完后,直接提交,我們用Prometheus+grafana可以里面看到實時報表。
6、案例介紹

這是一個典型的應用,Flink里面去計算的時候,他對這個數據進行過濾,完了之后進行一個遠程的call,這個遠程調用執行函數代碼,大多數這種情況就是一個開發就可以完成大數據的開發和這個函數接口的開發,就可以完成這樣一個活動的開發,整個活動開發的門檻就低了很多,真正實現了我們DevOps,就是開發能夠把整個流程自己走完。
四、微服務化&ServiceMesh
1、數據應用必走之路—微服務化
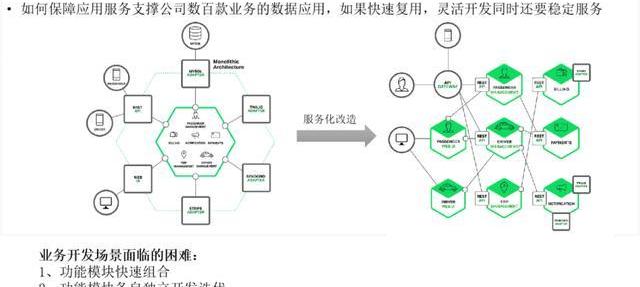
上面講的是OneData和OneFun的實現原理和機制,我們在內部是怎么去應用的,這套系統我們在游戲內部是大力推廣。
這里尤其是接口這塊,其實如果說要微服務化的話,大數據我們能做的也就是那樣了,能夠用yarn或者K8S去做資源的管控,和任務的管控,但真正去做服務治理還是在接口這塊。目前我們上下接口大概是三千五百個,每周新增50個接口。
所以我們在做的時候也考慮到。原來我們服務是一個個開發,但是沒有治理,現在我們加上服務還是一個個去開發,甚至有些服務我們會把它變成一個服務,但是我們加入了這個服務的治理。
好多人在提微服務,微服務如果沒有一個平臺去治理的話,將會是一種災難。所以微服務化給我們帶來便利的同時,也會給我們帶來一些問題,所以在我們的場景里面,微服務是非常好的,每一個接口就可以作為一個服務,這種是天然的微服務。
2、一體化服務治理設計
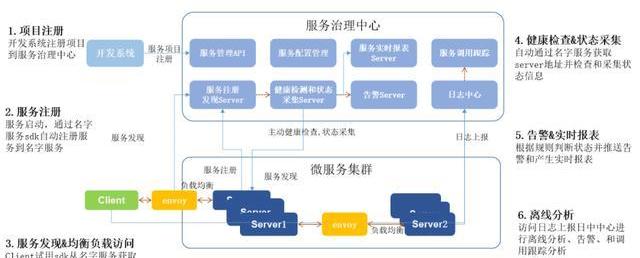
但是這種微服務的治理將會是我們很大的一個問題,所以我們花了很大的精力去做了一個微服務的治理系統,從項目注冊的時候,他就把項目注冊的微服務中心,并且把API注冊上來,然后在服務發布的時候,發到集群里的時候,這些服務都要主動的注冊到我們的名冊服務,就是Consoul。
但注冊到服務里不是作為服務路由來用的,而是到服務里后,我們在普羅米修斯這塊去做它的健康檢查和狀態采集,只要注冊上來,我立馬就能感知和把狀態采集過來,然后主要做實時報表和告警。
首先在服務的穩定性和健康度這塊我們有一個保障,另外一個就是服務的信息注冊到Consul里去后,我們有一個服務的網關,我們用的是envoy,其實內部我們還把它作為SideCar使用,后面會介紹。
注冊完了之后,envoy會把這個所有的負載進信息加載到這塊來,它去做它服務的路由,同時我們會把整個日志上報到日志中心去,包括網關的日志也會上傳到日志中心去,日志中心再去做離線的報表和實時的一些報警監控,
所以這里面我們還加了一個基于Consul的一個配置,就是我們包括server的實時控制都可以通過Consul去配置,配置完了后立馬能夠watch到,然后去執行。
這個是基本的服務治理,但現在我們的服務治理升級了,比這個要更好一點,基本的原理是這樣。
3、南北流量+東西流量的統一管控
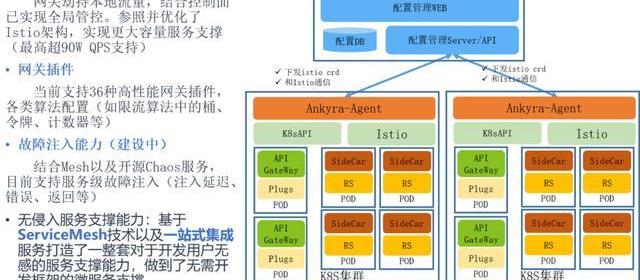
并且我們在這里面實現了一個對envoy的管控,我們說是服務治理,主要是對流量的一些治理,比如貧富負載策略,路由策略,熔斷,超時控制,故障注入等等一系列。
我們是通過Consul的配置管理,通過它能夠下發到我們的Agent,這個Agent再把這個數據能夠通過Istio的接口和k8s的API能夠下發到envoy,這里面就是APIGeteWay和SideCar都是envoy,所以我們通過Istio對他的XDS的接口寫入,就可以把所有的配置信息下發到這里。
這套系統能夠整個去管控整個集群,南北流量和東西流量的統一管控。這套系統我們未來準備開源,現在主要是內部在使用,而且這里面我們也做了圖形化的配置,所有envoy和Istio的配置我們都經過YAML轉Istio再轉UI的方式,把它圖形化了,在這塊能夠做統一的管控。
而且我們把Agent開發完了之后就是多集群的支持,就是多個K8s集群只要加入進來,沒問題可以去支持,我們管理APIGeteWay。
還有一塊是SideCar的管理,就是ServiceMash里的SideCar管理。我們剛才說的函數接口也好,規則接口也好,是一個server。
當然這里面還提到一個chaosmesh的功能,我們現在還在研究,我們準備在這套系統里把它實現了。
4、基于ServiceMesh的全鏈路流量分析
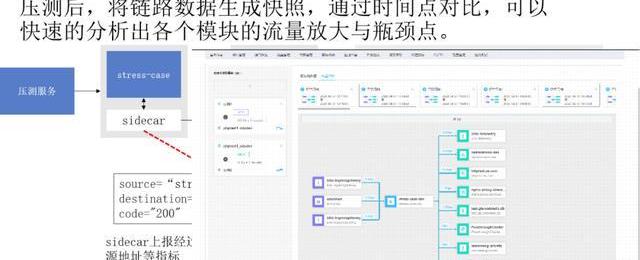
這是一個我們通過ServiceMesh做的分析,我們雖然可以宏觀地看出來我們接口對DB的壓力有多大,但實際上我們把流量導進來是我們對壓力的監控是不夠的,所以這種情況我們通過ServiceMesh,他對出口流量和進口流量的管控,然后可以把流量進行詳細的統計,統計完后可以生成一個快照,這次快照和下次快照之間的數據對比,入流量有多少的時候,對下面各個流量壓力有多少。
這是整個展示圖,我們有多個測試用例,這兩個測試用例之間我們可以算出來對下游的壓力的流量分析,后期對下游壓力的分析和下游資源的擴容、縮容都有非常大的價值。
5、案例介紹
最后再介紹下我們目前用這套系統實現的一些案例,大數據的游戲回歸,比如做一個游戲數據的回顧、任務系統、排行榜。
>>>>
Q&A
Q1:servicemesh是怎么部署的?主要用來解決什么問題?
目前我們在使用的ServiceMesh技術實現是istio,版本是1.3.6。這個版本還不支持物理機方式部署,所以我們是在k8s中部署使用,部署方式有2種,可以是直接使用istioctl命令安裝,或者是生成yaml文件后使用kubectl進行安裝。
Servicemesh的架構主要解決的問題是集群內東西流量的治理問題。同時servicemesh的Sidercar作為協議代理服務和可以屏蔽后面的服務開發技術棧,Sidercar后面的服務可以是各種語言開發,但是流量的管理和路由可以有統一的管控。
Q2:微服務治理架構能介紹一下嗎?
微服務治理架構在我看來可以分為兩類:
服務實例的治理,這個在目前的k8s架構下,基本都是由k8s來管理了,包含了服務實例的發布,升級,闊所容,服務注冊發現等等;
服務流量的治理,這一個大家通常說的服務治理,目前主要是由微服務網關和服務網格兩種技術來實現。服務網關實現集群內和集群外的流量治理,服務網格實現了集群內的流量治理。
Q3:開發人員主要具有什么樣的技術背景?
針對大數據開發人員,要使用我們這套系統只需要會sql語句和基本統計知識就可以了。
針對應用接口開發人員,要使用我們這套系統只需要會JavaScript或者Golang,會基本的正則表達式,了解http協議,會調試http的api接口就可以了。
Q4:實時計算,flink與spark選擇上有沒啥建議?
Spark在15,16年的時候我們也在大規模使用,也在實時計算中使用過,但是當時的版本在實時計算上還是比較弱,在500ms的批處理中還是會出現數據堆積,所以在實時性上會有一定的問題,Spark擅長在數據迭代計算和算法計算中。但是如果實時性要求不高而且有算法要求的場景中Spark還是不錯的選擇。
Flink在設計之初就是一種流失處理模型,所以在針對實時性要求較高的場景中Flink還是比較合適的,在我們內部測試發現Flink的流失計算吞吐確實要比Storm好很多,比Spark也是好很多,而且Flink目前的窗口機制針對實時計算中的窗口計算非常好用。所以一般實時計算或者對實時性要求較高的場景Flink還是比較推薦的。
Q5:游戲回放數據服務端存儲場景有么?
這種場景也是有的,游戲回放一般有2種方式,一種是錄屏傳輸回放,這種成本非常高,但是簡單且及時性比較好,另外一種是控制指令發回Server,在另外的服務中去恢復當時的場景,這種方式在成本相對較小,但是使用復雜。
Q6:回放場景下客戶端走什么協議將數據發送到服務端?
一般是游戲的私有協議。
面額為1美元的金元,重16.72克,直徑為12.7mm 面額為1美元的銀元,重26.37克,直徑38.1mm金屬貨幣和紙幣不一樣,持有金屬貨幣的人可以自己把金屬貨幣熔化回貴金屬.
1900/1/1 0:00:00人的本質是一切社會關系的總和這一規定,奠定了社會關系在馬克思現代性批判中的本體論地位。正是把現實性的社會關系理解為人的本質規定性,以之取代了抽象的類本質,馬克思才實現了從異化到物化的邏輯轉換.
1900/1/1 0:00:008月21日下午,經濟日報集團高級編輯、《證券日報》社副總編輯馬方業在《證券日報》社順和課堂,圍繞比特幣、區塊鏈技術以及央行數字貨幣DCEP等時下熱點內容,為報社員工上了別開生面的一課.
1900/1/1 0:00:00標題: 買賣BTC、usdt違法嗎?做比特幣、泰達幣等虛擬數字貨幣交易涉嫌詐騙、洗錢、掩飾隱瞞犯罪所得、非法經營罪、幫助信息網絡犯罪活動罪怎么判刑?判幾年? 本文分兩部分: 一:買賣或幫助別人買.
1900/1/1 0:00:002020年下半年,衍生品賽道已經成為各交易所必爭之地,后起之秀不斷挑戰原有市場,為投資者帶來新機會,新玩法.
1900/1/1 0:00:00華夏時報記者吳敏北京報道10月23日,由《華夏時報》、水皮雜談、華夏時報金融研究院以及Cointelegraph中文共同主辦的“探索變革,服務產業2020華夏時報產業區塊鏈峰會”在北京召開.
1900/1/1 0:00:00


