






 BTC/HKD+0.33%
BTC/HKD+0.33% ETH/HKD-0.43%
ETH/HKD-0.43% LTC/HKD+0.71%
LTC/HKD+0.71% DOT/HKD+1.62%
DOT/HKD+1.62% ADA/HKD+0.57%
ADA/HKD+0.57% SOL/HKD+0.23%
SOL/HKD+0.23% XRP/HKD+2.06%
XRP/HKD+2.06% DOGE/US+3.27%
DOGE/US+3.27%摘要
隨著AI以超乎想象的速度演化,必將引起對AI利劍的另一“刃”——信任——的擔憂。首先是隱私方面:AI時代,人類從數據隱私的角度如何信任AI?也許AI模型的透明度是更為擔憂的關鍵:類似大規模語言模型的涌現能力,對人類來說無異于一個無法看透的科技“黑匣子”,一般用戶并不能理解模型是如何運行的、運行結果又是如何獲得的——更麻煩的是,作為用戶可能并不知道服務商提供的AI模型是否如承諾的那樣運行。尤其是在一些敏感數據上應用AI算法和模型,如醫療、金融、互聯網應用等,AI模型是否具有偏見(甚至惡意導向)、或者服務商是否按照承諾那樣準確無誤地運行模型(以及相關參數),成為用戶最為關心的問題。零知識證明技術在這方面有著針對性的解決方案,于是零知識機器學習(ZKML)成為最新崛起的發展方向。
綜合考慮到計算的完整性、啟發性優化以及隱私,零知識證明和AI的結合下,零知識機器學習(Zero-Knowledge Machine Learning,ZKML)應運而生。在AI生成內容越來越逼近與人類產生的內容的時代,零知識密證明的技術特點可以幫助我們確定特定內容是通過特定模型產生的。對于隱私保護,零知識證明技術特別重要,即可以在不泄露用戶數據輸入或模型具體細節的情況下完成證明和驗證。
零知識證明應用于機器學習的五種方式:計算完整性、模型完整性、驗證、分布式訓練和身份驗證。最近大型語言模型 (LLM) 的快速發展表明這些模型變得越來越智能,這些模型完善了算法與人類的重要接口:語言。通用人工智能 (AGI) 的趨勢已經不可阻擋,但就現在的模型訓練結果來看,AI可以在數字交互中完美模仿高能力的人類——且在快速的演進中以不可想象的速度達到超越人類的水平,使得人類不得不驚嘆這種進化速度、甚至產生被AI迅速替代的憂慮。
社區開發者利用ZKML對Twitter推薦功能進行驗證,具有一定啟發性。Twitter的“For You”推薦功能利用一種AI推薦算法,將每天發布的大約 5 億條推文提煉成少數幾條熱門推文,最終顯示在用戶主頁的時間軸上。2023年3月底,Twitter開源該算法,但因模型細節未公開,用戶依然無法驗證算法是否準確、完整運行。社區開發者Daniel Kang等利用密碼學工具ZK-SNARKs來檢查Twitter推薦算法是否正確、完整運行而無需公開算法細節——這正是零知識證明最吸引人之處,即不透露關于對象的任何具體信息(零知識)的前提下證明該信息的可信性。最理想的情況是,Twitter可以使用ZK-SNARKS 來發布其排名模型的證明——證明當該模型應用于特定用戶和推文時,它會產生特定的最終輸出排名。該證明則是該模型可信的基礎:用戶可以自行驗證模式算法的計算是否按承諾執行——或者交給第三方來進行審計。這一切都是在不公開模型參數權重細節的基礎上進行。也就是說,利用官方公布的模型證明,用戶對具體的有疑問的推文,利用該證明來驗證特定推文是否按照模型承諾那樣誠實運行。
摩根大通投資策略主席:不管比特幣如何擴張,如何流行都不能讓人感到滿意:金色財經報道,金融巨頭摩根大通投資策略主席Michael Cembalest在最近的一次采訪中表示,他對比特幣和加密貨幣的世界并不瘋狂,暗示盡管比特幣如何擴張,如何流行,但這種貨幣不會讓所有人都感到滿意。Cembalest 表示所表達的觀點是他自己的觀點,而不是摩根大通的觀點。不喜歡世界排名第一的數字貨幣,原因有兩個。首先是因為它的波動性,他說這阻止了比特幣“進入與價值投資相一致的范圍”。另一個原因是因為比特幣并沒有像許多分析師讓我們相信的那樣證明自己是對沖通脹的工具。(livebitcoinnews)[2022/2/14 9:49:52]

1. 核心觀點
隨著AI以超乎想象的速度演化,必將引起對AI利劍的另一“刃”——信任——的擔憂。首先是隱私方面:AI時代,人類從隱私的角度如何信任AI?也許AI模型的透明度是更為擔憂的關鍵:類似大規模語言模型的涌現能力,對人類來說無異于一個無法看透的科技“黑匣子”,一般用戶并不能理解模型是如何運行的、運行結果又是如何獲得的(本身模型就充滿了難以理解或者預測的能力)——更麻煩的是,作為用戶可能并不知道服務商提供的AI模型是否如承諾的那樣運行。尤其是在一些敏感數據上應用AI算法和模型,如醫療、金融、互聯網應用等,AI模型是否具有偏見(甚至惡意導向)、或者服務商是否按照承諾那樣準確無誤地運行模型(以及相關參數),成為用戶最為關心的問題。
零知識證明技術在這方面有著針對性的解決方案,于是零知識機器學習(ZKML)成為最新崛起的發展方向。本文探討了ZKML技術的特點、潛在應用場景和一些具有啟發性的案例,并對ZKML的發展方向及可能的產業影響做了研究闡述。
2. AI利劍的“另一刃”:如何信任AI?
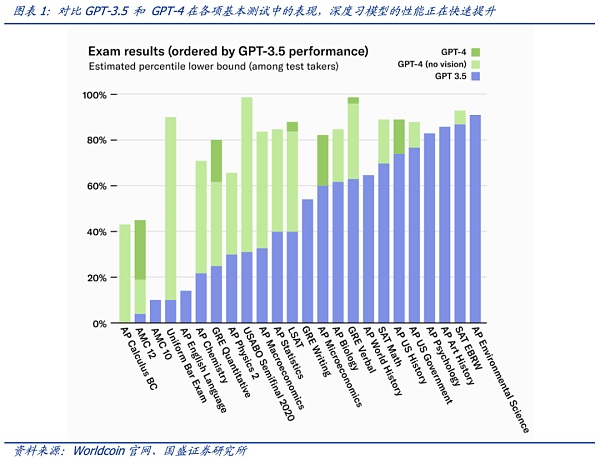
人工智能的能力正在迅速接近人類,并且已經在許多利基領域超越了人類。最近大型語言模型 (LLM) 的快速發展表明這些模型變得越來越智能,這些模型完善了算法與人類的重要接口:語言。通用人工智能 (AGI) 的趨勢已經不可阻擋,但就現在的模型訓練結果來看,AI可以在數字交互中完美模仿高能力的人類——且在快速的演進中以不可想象的速度達到超越人類的水平。語言模型最近取得了重大進展,以ChatGPT為代表的產品表現驚艷,在大多數常規評估中達到了人類能力的 20% 以上,當比較僅相隔幾個月的GPT-3.5 和 GPT-4 時,使得人類不得不驚嘆這種進化速度。但另一面則是對AI能力失控的擔憂。
Craig Wright:PoW是指導網絡存在分歧時如何行動的信號:Craig Wright在其最新的博客文章中解釋了為什么工作量證明(Proof-of-Work,PoW)是至關重要的。他表示,工作量證明是一種重要的信號,它告訴網絡上的節點,當網絡上存在分歧時,該如何行動。重要的是要區分這些節點不是對網絡規則投票,而是執行規則。他說,“工作量證明是一種經濟信號,從理論上講是從游戲的角度去激勵玩家的誠實行為,或者提供一種懲罰機制。”[2020/8/20]
首先是隱私方面。AI時代,隨著人臉識別等技術的發展,用戶在體驗AI服務的同時,時刻都在擔心數據泄露風險。這給AI的推廣和發展帶來了一定阻礙——從隱私的角度如何信任AI?
也許AI模型的透明度是更為擔憂的關鍵。類似大規模語言模型的涌現能力,對人類來說無異于一個無法看透的科技“黑匣子”,一般用戶并不能理解模型是如何運行的、運行結果又是如何獲得的(本身模型就充滿了難以理解或者預測的能力)——更麻煩的是,作為用戶可能并不知道服務商提供的AI模型是否如承諾的那樣運行。尤其是在一些敏感數據上應用AI算法和模型,如醫療、金融、互聯網應用等,AI模型是否具有偏見(甚至惡意導向)、或者服務商是否按照承諾那樣準確無誤地運行模型(以及相關參數),成為用戶最為關心的問題。如社交應用平臺是否按照“一視同仁”的算法進行相關推薦?來自金融服務商AI算法的推薦是否如承諾的那樣準確、完整運行?AI的推薦的醫療服務方案是否有不必要的消費?服務商是否接受對AI模型進行審計?
簡單來說,一方面用戶并不知道服務商提供的AI模型的真實情況,同時非常擔心模型并非“一視同仁”,AI模式被認為加入一些帶有偏見或者其他導向的因素,會給用戶帶來未知的損失或負面影響。
另一方面,AI的自我演化速度似乎越來越難以預測,越來越強大的AI算法模型似乎越來越超出人控制的可能,因此信任問題成為AI這把利劍的另一“刃”。
需要從數據隱私、模型透明度、模型可控性等角度建立用戶對AI的信任。用戶需要擔心隱私保護以及算法模型是否如承諾的那樣準確、完整運行;然而這并非易事,就模型透明度而言,模型提供商基于商業秘密等角度,對模型的審計和監督方面存有顧慮;另一方面算法模型自身的演化并不易控,這一點不可控性也需要考慮到。
以太坊核心開發者:沒人詢問開發人員如何看待提高Gas上限問題:7月20日,以太坊核心開發者Péter Szilágyi發推稱,很驚奇的是,那些“提高Gas上限”的文章中,沒有一個文章詢問任何開發人員如何看待這個問題。[2020/7/20]
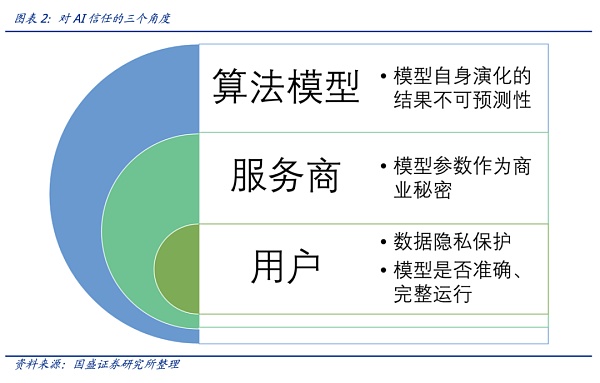
用戶數據隱私保護的角度,在我們之前的報告如《Web3.0驅動下的AI和數據要素:開放、安全與隱私》也多有研究,Web3.0的一些應用在這方面極具啟發性——即在完整用戶數據確權、數據隱私保護的前提下進行AI模型訓練。
但目前市場為Chatgpt這類大模型的驚艷表現而折服,還未考慮到模型自身的隱私問題、算法“涌現”特征的演化帶來的模型的信任問題(以及不可控性帶來的信任),但另一層面,用戶對所謂算法模型的準確、完整和誠實運行一直持懷疑態度。因此,AI的信任問題,應該從用戶、服務商和模型不可控性三個層面來解決。
3. ZKML:零知識證明與AI結合帶來信任
3.1.零知識證明:zk-SNARKS、zk-STARK等技術日趨成熟
零知識證明(Zero Knowledge Proof,ZKP)最早由MIT的Shafi Goldwasser和Silvio Micali在1985年一篇名為《互動式證明系統的知識復雜性》的論文中提出。作者在論文中提到,證明者(prover)有可能在不透露具體數據的情況下讓驗證者(verifier)相信數據的真實性。公共的函數f(x)和一個函數的輸出值y,Alice對Bob說她知道x值,但是Bob不信。為此,Alice使用零知識證明算法,來生成一個證明。Bob驗證這個證明,確認Alice是不是真的知道滿足函數f的x。
舉例來說,利用零知識證明,可以不知道小明考試的成績,而可以知道其成績是否滿足用戶的要求——比如是否及格、是否填空題正確率超過60%等等。在AI領域,結合零知識證明,則可以對AI模型有可靠的信任工具。
零知識證明可以是交互式的,即證明者面對每個驗證者都要證明一次數據的真實性;也可以是非交互式的,即證明者創建一份證明,任何使用這份證明的人都可以進行驗證。
OKEx金融市場總監:加密貨幣的未來取決于CBDC在未來如何發展:5月24日消息,OKEx金融市場總監Lennix Lai表示,適應中國的CBDC并不是那么困難,因為現金的使用已經有所下降,這要歸功于支付寶和微信支付等電子支付系統的進入。Lai指出,鑒于中國一直在使用需要KYC和其他安全流程的電子支付的事實,中國的金融隱私概念早已不復存在,但當其他國家中央銀行在發行CBDC時,這可能會成為一個問題。另一方面,中國CBDC直接在中央銀行的權力之下并且不提供任何金融隱私這一事實可能會促使人們開始轉向加密貨幣。因此,中國CBDC的啟動確實可以促進并使人們意識到主流加密貨幣的用例和重要性。此外,他表示,比特幣、Ripple和其他加密貨幣的未來取決于CBDC在未來如何發展。如果人們意識到金融隱私的需要,他們可能會涌向比特幣,但在那些金融隱私存在已久的國家,這種去中心化的貨幣可能會被邊緣化。(AMBcrypto)[2020/5/24]
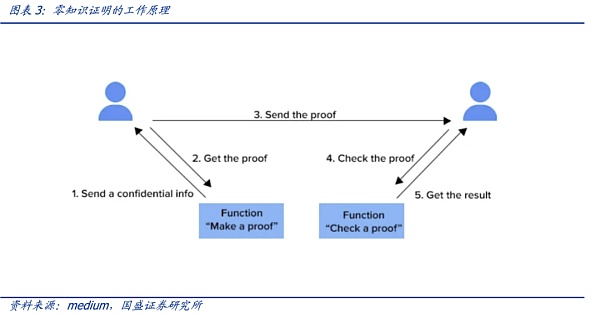
零知識分為證明和驗證兩部分,一般來說證明是準線性的,即驗證是T*log(T)的。
假設驗證時間是以交易數量對數的平方,那么10000筆交易一個塊的機器驗證時間是
VTime = ( )2 ~ (13.2)2 ~ 177 ms;現在將塊大小增加一百倍(達到100萬tx/塊),驗證器的新運行時間是VTime = (log2 1000000)2 ~ 202 ~ 400 ms。因此,我們能看到其超強的可拓展性,這就是為什么說,從理論上tps能夠達到無限的原因。
驗證是非常快的,而所有的難點就在于生成證明這一部分。只要生成證明的速度跟得上,那么鏈上驗證就很簡單。零知識證明目前有多種實現方式,如zk-SNARKS、zk-STARKS、PLONK以及Bulletproofs。每種方式在證明大小、證明者時間以及驗證時間上都有自己的優缺點。
零知識證明越復雜、越大,則性能越高,驗證所需的時間越短。如下圖,STARKs和Bulletproofs無需可信設置,隨著交易數據量從1TX激增至10000TX,后者證明的大小增加的更少。Bulletproofs的優點是證明的大小是對數變換(即使f和x很大),有可能將證明存入區塊,但其驗證的計算復雜度是線性的。可見各類算法都有很多要權衡的關鍵點,亦有很多待升級的空間,然而在實際運行過程中,生成證明的難度遠比想象中的要大,因此現在行業都致力于解決生成證明的問題。
動態 | 社科院法學所刊文《對“去中心化”的區塊鏈如何監管》:中國社科院法學所趙磊在《經濟參考報》發表題為《對“去中心化”的區塊鏈如何監管》的文章。文章指出,對區塊鏈技術的監管,應該分為兩個層面:一是結合區塊鏈技術的具體應用場景,分行業進行監管;另一是針對區塊鏈,制定專門的技術標準,以實現區塊鏈技術的規范、統一。而判斷某種商業活動或者社會管理活動是否可以應用區塊鏈,至少應該從以下兩方面進行衡量:一方面是區塊鏈技術只能在虛擬空間中應用;另一方面是區塊鏈技術無論在何種場景中應用,必須符合其去中心化、共識機制與分布式記賬等技術特征。[2019/1/10]
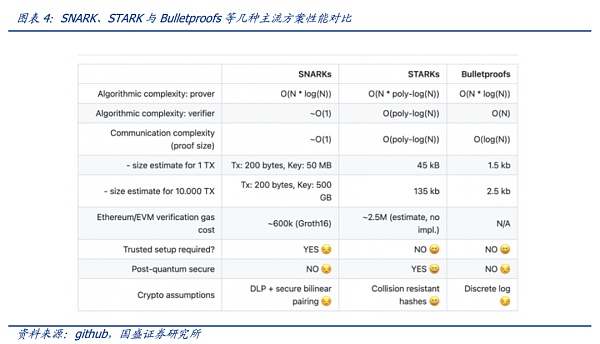
雖然零知識證明技術的發展還不足以匹配類似大語言模型(LLM)的規模,但其技術實現有著啟發性的應用場景。特別是在AI雙刃劍的發展狀況下,零知識證明為AI信任化提供了可靠的解決方案。
3.2.零知識機器學習(ZKML):去信任化的AI
在AI生成內容越來越逼近于人類所產生的內容的時代,零知識密證明的技術特點可以幫助我們確定特定內容是通過將特定模型產生的。對于隱私保護,零知識證明技術特別重要,即可以在不泄露用戶數據輸入或模型具體細節的情況下完成證明和驗證。綜合考慮到計算的完整性、啟發性優化以及隱私,零知識證明和AI的結合下,零知識機器學習(Zero-Knowledge Machine Learning,ZKML)應運而生。
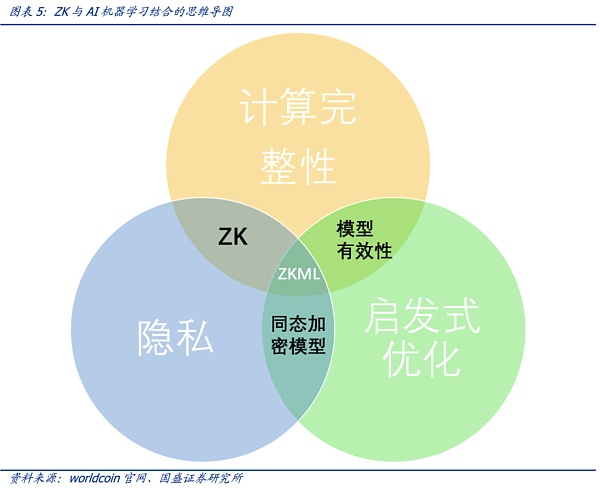
以下是零知識證明應用于機器學習的五種方式。除計算完整性、模型完整性和用戶隱私這些基礎功能外,零知識機器學習還能帶來分布式訓練——這將促進AI與區塊鏈的融合,以及人來在AI叢林里的身份證明(該部分可以詳見我們的報告《OpenAI創始人的Web3愿景:Worldcoin打造AI數字通行證》)。

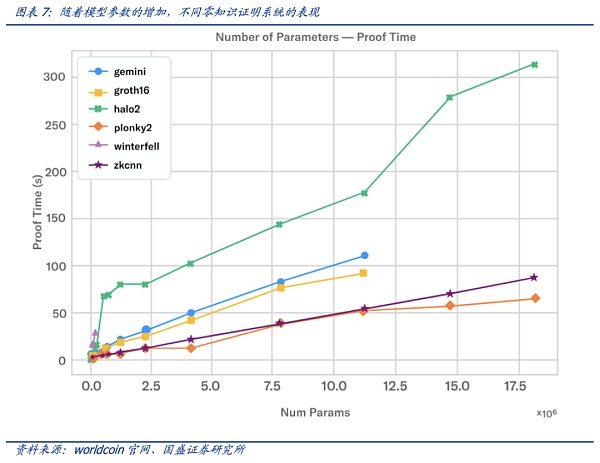
AI大模型對算力的需求是有目共睹的,而此時由將ZK證明穿插到AI應用中來,對硬件算力則帶來新的需求。零知識系統的當前技術水平與高性能硬件相結合,依舊無法證明與當前可用的大型語言模型(LLM)一樣大的東西,但已經取得了一些進展創建較小模型的證明。根據Modulus Labs團隊針對各種不同規模的模型對現有的 ZK 證明系統進行了測試。如plonky2等證明系統,可以在功能強大的 AWS 機器上運行約 50 秒,為大約 1800萬參數規模的模型創建證明。
就硬件而言,ZK技術目前的硬件選擇包括GPU、FPGA 或 ASIC。需要注意的是零知識證明仍處于早期發展階段,目前仍然很少有標準化,且算法也在不斷更新變化中。每種算法都有其特點,適合于不同的硬件,且隨著項目發展需求每種算法都會有一定程度改進,因此很難去具體評估哪種算法最優。
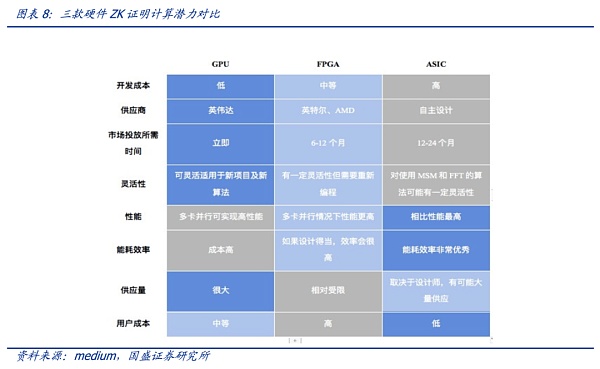
需要注意的是,ZK與AI大模型的結合方面,還未有明確的研究對現有的硬件系統進行評估,因此,未來硬件需求方面還存在較大的變數與潛力。
3.3.啟發性案例:驗證Twitter推薦排名算法
Twitter的“For You”推薦功能利用一種AI推薦算法,將每天發布的大約 5 億條推文提煉成少數幾條熱門推文,最終顯示在用戶主頁的“For You”時間軸上。該推薦從推文、用戶和參與數據中提取潛在信息以便能夠提供更相關的推薦。2023年3月底,Twitter開源了推薦功能“For You”在時間軸上選擇和排名帖子的算法。推薦流程大致如下:
1)從用戶與網站的交互中生成用戶行為特征,從不同的推薦來源獲取最佳推文;
2)使用AI算法模型對每條推文進行排名;
3)應用啟發功能和過濾器,例如過濾掉來自用戶已阻止的推文內容和已經看過的推文等。
該推薦算法最核心的模塊是負責構建和提供 For You 時間線的服務—— Home Mixer。該服務充當連接不同候選源、評分函數、啟發式方法和過濾器的算法主干。
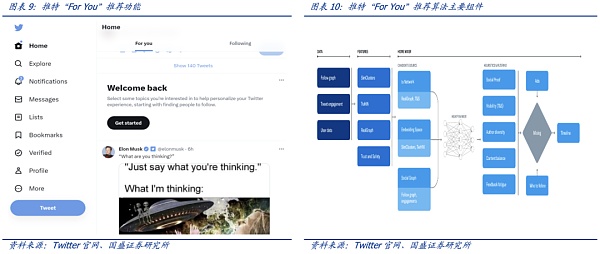
“For You”推薦功能根據大約 1500 個可能相關的候選推薦,預測每個候選推文的相關性并進行評分。推特官網稱在此階段,所有候選推文都受到平等對待。而最核心的排名則是通過一個約 4800萬參數的神經網絡實現的,該神經網絡在推文交互上持續訓練以優化。這種排名機制考慮了數千個特征并輸出十個左右的標簽來為每條推文打分,其中每個標簽代表參與的概率,然后根據這些分數對推文進行排名。
雖然這是推特推薦算法邁向透明的重要一步,但用戶依然無法驗證算法是否準確、完整運行——一個主要原因是用于對推文進行排名的算法模型中具體的權重細節以保護用戶隱私的緣由而未公開。因此,算法的透明度依舊存疑。
利用ZKML(零知識機器學習)技術,可以在Twitter 不公開算法模型權重細節的情況下證明是否準確、完整運行(模型及其參數對不同用戶是否“一視同仁”),這使得在算法模型隱私保護和透明性之間取得了很好的平衡。
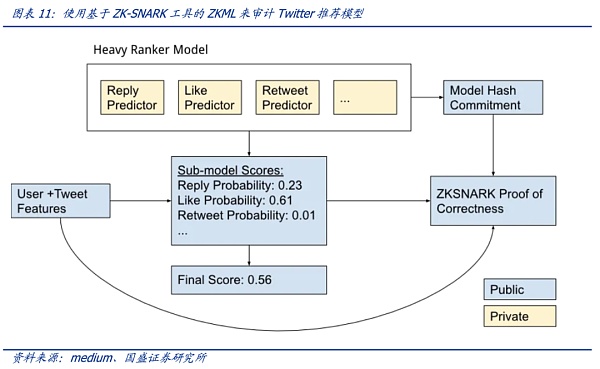
假設用戶認為“For You”推薦功能的時間線值得懷疑——認為某些推文的排名應該更高(或低)。如果Twitter 能夠上線ZKML證明功能,用戶可以利用官方給出的證明來自行檢查懷疑的推文與時間軸中的其他推文相比排名如何(計算出的分數對應著排名),如果排名與模型的分數不符,則表示對這些特定推文的算法模型并非誠實運行(而是人為地在一些參數上有變化)。可以這樣理解,官方雖然不公布模型的具體細節,但是根據模型給出了一把魔法棒(模型產生的證明),任何推文利用這個魔法棒都能展現相關排名分數——而根據這個魔法棒卻無法還原模型隱私細節。因此,官方模型的細節隱私得到保護的情況下獲得審計。

站住模型的角度,在保護模型隱私的情況下,利用ZKML技術,依舊可以使模型獲得審計和用戶的信任。
吉時通信
個人專欄
閱讀更多
金色早8點
Odaily星球日報
金色財經
Block unicorn
DAOrayaki
曼昆區塊鏈法律
Tags:區塊鏈TERTTEWIT區塊鏈工程專業學什么課程的anticounterfeitchainMirrored Twittergowithmi
價格:比特幣交易價格為 2.68 萬美元,但 Oanda 高級市場分析師 Craig Erlam 對未來幾個月比特幣價格在不確定的行業和經濟新聞中大幅上漲持懷疑態度.
1900/1/1 0:00:00Middleware OverviewMiddleware 是指在 Web3.0 技術棧中起到連接、增強和補充功能的重要組成部分。它們扮演著橋梁的角色,連接著區塊鏈技術與應用的世界.
1900/1/1 0:00:00作者:Defi_Mochi,DeFi KOL;翻譯:金色財經xiaozou有這樣一個協議,在發布后短短的3個月內:DEX交易量將突破310億,預計每年賺取費用700萬美元,至今還沒有代幣.
1900/1/1 0:00:002023年6月23日,亞太區塊鏈聯會、金色財經等多家Web3企業訪問香港數碼港,并就Web3項目落地合作和香港數碼港舉行交流會議.
1900/1/1 0:00:00直到今天,區塊鏈技術依舊可以說是個新興的技術,盡管區塊鏈相關的基本概念(密碼學、去中心化、點對點網絡和交易)已經被研究了數十年,但直到 2008 年比特幣誕生之后.
1900/1/1 0:00:00原文:bitcoinist,編譯:區塊鏈騎士Uniswap,一個知名的去中心化交易所,推出了它的第四個版本.
1900/1/1 0:00:00


